
- 분류 전체보기 (594)

YOGYUI
공공데이터포털::대기오염정보 조회 (REST API) 본문

공공데이터포털에서 전국의 대기오염정보를 가져와보자
공공데이터포털 관련 글을 많이 쓰다보니 서론 쓰는 것도 힘들다
1. API 활용신청

정식 데이터 타이틀은 "한국환경공단_에어코리아_대기오염정보"
URL: https://www.data.go.kr/tcs/dss/selectApiDataDetailView.do?publicDataPk=15073861
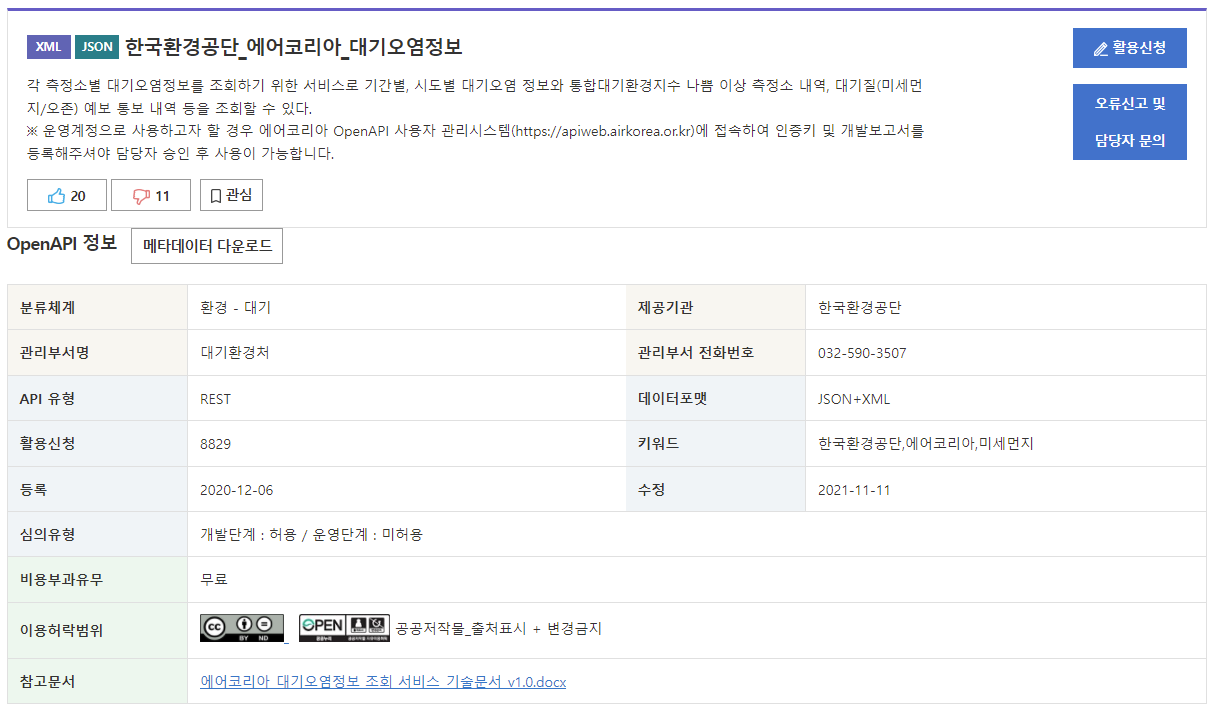
2020년 12월에 공공데이터포털에 등록되었는데, 8000건이 넘게 활용신청된 아주 따끈따끈하고 핫한 API !!
미세먼지가 1년 내내 우리를 괴롭히니 어쩔 수가 없는건가 ㅠㅠ
API 활용신청(방법은 링크 참고)하고 인증키 획득
인증키를 메모장에 복사해두자
2. API 명세 확인
API 명세서는 워드 문서로 제공되는데, 상세하게 기입되어 있어 문서 한장만으로도 충분히 구현 가능하다
(한국환경공단은 일을 꽤 잘하는 것 같다)
5종류의 서비스를 제공하고 있다
서비스별로 데이터 생성주기가 상이한 경우가 있으니 데이터 갱신(refresh) 주기 설정에 활용하면 된다
(개발계정의 경우 서비스별로 일일트래픽이 500회로 한정되어있으나, 이렇게 데이터 생성주기가 길 경우 요청이 들어올때마다 트래픽 발생하지 않고 로컬/서버에 미리 저장해둔 값을 리턴하면 된다)
- 대기질 예보통보 조회 (상세URL: getMinuDustFrcstDspth)
데이터 생성주기: 1일 4회 (오전 5시, 오전 11시, 오후 5시, 오후 11시, 각 시별 10분 내외) - 초미세먼지 주간예보 조회 (상세URL: getMinuDustWeekFrcstDspth)
데이터 생성주기: 1일 1회 오후 5시 30분 내외 - 측정소별 실시간 측정정보 조회 (상세URL: getMsrstnAcctoRltmMesureDnsty)
데이터 생성주기: 매시 15분 내외 - 통합대기환경지수 나쁨 이상 측정소 목록 조회 (상세URL: getUnityAirEnvrnIdexSnstiveAboveMsrstnList)
데이터 생성주기: 매시 15분 내외 - 시도별 실시간 측정정보 조회 (상세URL: getCtprvnRltmMesureDnsty)
데이터 생성주기: 매시 15분 내외
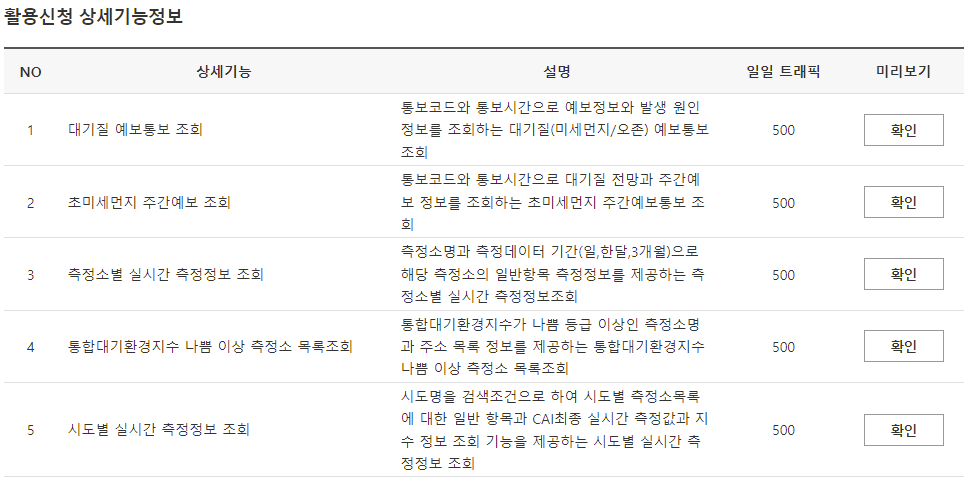
각 기능별로 request (GET) 파라미터와 결과 출력물이 조금씩 상이한게 있으므로, 제대로 된 결과를 얻기 위해서는 상세문서를 잘 살펴봐야 한다
request할 공통 URL은 http://apis.data.go.kr/B552584/ArpltnInforInqireSvc 이고, 뒤에 상세 URL을 붙이면 5개 기능 각각에 접근할 수 있다
대기오염측정지표로는 \(SO_{2}\)(이산화황=아황산가스), \(CO\)(일산화탄소), \(O_{3}\)(오존), \(NO_{2}\)(이산화질소), \(PM_{10}\)(미세먼지), \(PM_{2.5}\)(초미세먼지) 6개 항목을 사용하며 각각의 단위는 다음과 같다
| \(SO_{2}\) | \(CO\) | \(O_{3}\) | \(NO_{2}\) | \(PM_{10}\) | \(PM_{2.5}\) |
| \(ppm\) | \(ppm\) | \(ppm\) | \(ppm\) | \(\mu g/m^{3}\) | \(\mu g/m^{3}\) |
참고로 미세먼지를 가리키는 PM은 particulate matter의 약자로 '미세한 입자'를 뜻하며, 뒤에 붙은 숫자는 입자의 지름을 가리키며 마이크로미터(\(\mu m\)) 단위이다
즉 \(PM_{10}\)은 입자 지름이 \(10\mu m\) 이하인 미세입자, 즉 \(PM_{2.5}\)은 입자 지름이 \(2.5\mu m\) 이하인 미세입자의 농도를 가리킨다 (참고로 머리카락의 직경이 대략 \(100\mu m\))
3. 테스트 코드 작성
모든 기능들에 공통적으로 적용되는 파라미터부터 알아보자
[필수 파라미터]
ServiceKey: 공공데이터포털에서 발급받은 인증키
[선택(옵션) 파라미터]
returnType: 데이터 반환 타입 ("xml", "json" 중 선택)
numOfRows: 한 페이지 결과 수
pageNo: 페이지 번호
데이터 레코드가 많을 경우 여러 페이지로 나뉘게 되어 각 페이지를 조회할 수 있는데, 대기오염정보 데이터는 레코드 수가 그렇게 많지 않으니 페이지로 조회할 경우 한 페이지 결과 수를 10000 정도로 두고 한번에 받아봐도 무방한 것 같다
반환데이터로는 서비스별로 상이한데, 전부 기입하면 글이 너무 길어지니 자세한 사항은 명세서를 참고하도록 하자 (예제코드에서 어떤 항목이 있는지 확인할 수 있다)
코드는 모두 Python으로 작성하고, Open API 호출에 편하게 사용할 수 있는 requests 패키지를 활용하며, XML 파싱을 위해 BeautifulSoup 패키지를 활용하고, 결과 데이터를 핸들링하기 위해 pandas 패키지를 활용하도록 한다
3.1. 대기질 예보통보
상세 URL: getMinuDustFrcstDspth
[필수 파라미터]
없음
[선택(옵션) 파라미터]
searchDate: 조회 날짜 (YYYY-mm-dd 포맷 문자열)
ver: "1.1"을 입력하면 한반도 대기질 예측모델결과 애니메이션 이미지 URL을 얻을 수 있다
※ 조회날짜 사용 시, numOfRows와 pageNo는 무시되며, 조회날짜를 사용하지 않으면 한달간의 예보통보 발령 히스토리를 얻을 수 있다
InformCode: 통보 코드 (해보니 의미없는 것 같다... 어떤 값을 넣던지 PM10, PM25 결과를 한번에 받는다)
[sample_getMinuDustFrcstDspth.py]
import requests
# 대기질 예보통보 조회
url_base = "http://apis.data.go.kr/B552584/ArpltnInforInqireSvc"
url_spec = "getMinuDustFrcstDspth"
url = url_base + "/" + url_spec
api_key_utf8 = "Your API Key from data.go.kr"
api_key_decode = requests.utils.unquote(api_key_utf8, encoding='utf-8')
search_date = "2022-01-11"
params = {
"serviceKey": api_key_decode,
"returnType": "xml",
"searchDate": search_date,
"ver": "1.1"
}
response = requests.get(url, params=params)테스트를 위해 2022년 1월 11일의 대기질 예보통보 데이터를 조회해봤다
GET 결과 상태 코드(status_code)가 200이면 정상적으로 결과값이 들어온 것이다
In [1]: response.status_code
Out[1]: 200returnType 파라미터를 xml로 설정했으므로, 결과 텍스트는 다음과 같이 생겨먹었다 (너무 길어서 일부만 발췌)
In [2]: response.text
Out[2]: '<?xml version="1.0" encoding="UTF-8"?>\r\n<response>\n <header>\n <resultCode>00</resultCode>\n <resultMsg>NORMAL_CODE</resultMsg>\n </header>\n <body>\n <items>\n <item>\n <imageUrl4>https://www.airkorea.or.kr/file/proxyImage?fileName=2022/01/11/AQFv1_15h.20220111.KNU_09_01.PM2P5.1hsp.2022011121.png</imageUrl4>\n ...response.text는 str형으로 인코딩된 문자열을, response.content는 raw 문자열을 bytes형으로 가져올 수 있다. 문자열이 깨진다면
response.content.decode(encoding='utf-8')과 같이 인코딩을 지정해주면 된다 (xml 태그에 인코딩이 "UTF-8"과 같이 기입되어 있는것이 일반적이다)
이제 beautifulsoup를 통해 xml 형식의 문자열을 파싱해주자 (파서는 lxml 사용)
from bs4 import BeautifulSoup
xml = BeautifulSoup(response.text, "lxml")In [3]: type(xml)
Out[3]: bs4.BeautifulSoup
In [4]: xml.find('header')
Out[4]:
<header>
<resultcode>00</resultcode>
<resultmsg>NORMAL_CODE</resultmsg>
</header><header> 태그에서 API 호출 결과를 확인할 수 있다 (code 00이면 정상)
이제 <items> 태그의 모든 자식 <item> 태그들을 파싱해서 pandas dataframe으로 변환해보자
(자식 태그명과 범주명은 API 명세서를 참고하면 된다)
import pandas as pd
def convert_string(item_, key_):
try:
return item_.find(key_.lower()).text.strip()
except AttributeError:
return None
items = xml.findAll("item")
item_list = []
for item in items:
item_dict = {
'통보시간': convert_string(item, "dataTime"),
'통보코드': convert_string(item, "informCode"),
'예보개황': convert_string(item, "informOverall"),
'발생원인': convert_string(item, "informCause"),
'예보등급': convert_string(item, "informGrade"),
'행동요령': convert_string(item, "actionKnack"),
'첨부파일명1': convert_string(item, "imageUrl1"),
'첨부파일명2': convert_string(item, "imageUrl2"),
'첨부파일명3': convert_string(item, "imageUrl3"),
'첨부파일명4': convert_string(item, "imageUrl4"),
'첨부파일명5': convert_string(item, "imageUrl5"),
'첨부파일명6': convert_string(item, "imageUrl6"),
'첨부파일명7': convert_string(item, "imageUrl7"),
'첨부파일명8': convert_string(item, "imageUrl8"),
'첨부파일명9': convert_string(item, "imageUrl9"),
'예측통보시간': convert_string(item, "informData")
}
item_list.append(item_dict)
df = pd.DataFrame(item_list)In [5]: df.shape
Out[5]: (20, 16)최종 데이터 생성 시간은 오후 11시 이후에 데이터를 조회하면 총 20개 레코드를 볼 수 있다
In [6]: df[['통보시간', '통보코드', '예측통보시간']]
Out[6]:
통보시간 통보코드 예측통보시간
0 2022-01-11 23시 발표 PM10 2022-01-11
1 2022-01-11 23시 발표 PM10 2022-01-12
2 2022-01-11 23시 발표 PM10 2022-01-13
3 2022-01-11 23시 발표 PM25 2022-01-11
4 2022-01-11 23시 발표 PM25 2022-01-12
5 2022-01-11 23시 발표 PM25 2022-01-13
6 2022-01-11 17시 발표 PM10 2022-01-11
7 2022-01-11 17시 발표 PM10 2022-01-12
8 2022-01-11 17시 발표 PM10 2022-01-13
9 2022-01-11 17시 발표 PM25 2022-01-11
10 2022-01-11 17시 발표 PM25 2022-01-12
11 2022-01-11 17시 발표 PM25 2022-01-13
12 2022-01-11 11시 발표 PM10 2022-01-11
13 2022-01-11 11시 발표 PM10 2022-01-12
14 2022-01-11 11시 발표 PM25 2022-01-11
15 2022-01-11 11시 발표 PM25 2022-01-12
16 2022-01-11 05시 발표 PM10 2022-01-11
17 2022-01-11 05시 발표 PM10 2022-01-12
18 2022-01-11 05시 발표 PM25 2022-01-11
19 2022-01-11 05시 발표 PM25 2022-01-12각 통보시간 (5시, 11시, 17시, 23시)별로 미세먼지(PM10), 초미세먼지(PM25) 각각에 대한 당일 통보 및 2일뒤까지의 통보 데이터가 담겨있다 (내일, 모레 "예측"의 의미)
레코드 한개를 살펴보자
In [7]: df.iloc[0]
Out[7]:
통보시간 2022-01-11 23시 발표
통보코드 PM10
예보개황 ○ [미세먼지] 전 권역이 '좋음'∼'보통'으로 예상됩니다.
발생원인 ○ [미세먼지] 원활한 대기 확산으로 대기 상태가 대체로 '보통' 수준일 것으로 예상됩니다.
예보등급 서울 : 보통,제주 : 좋음,전남 : 좋음,전북 : 좋음,광주 : 좋음,경남 : 좋음,경북 : 보통,울산 : 보통,대구 : 보통,부산 : 보통,충남 : 좋음,충북 : 보통,세종 : 좋음,대전 : 보통,영동 : 좋음,영서 : 보통,경기남부 : 좋음,경기북부 : 좋음,인천 : 좋음
행동요령
첨부파일명1 https://www.airkorea.or.kr/file/proxyImage?fileName=2022/01/11/AQFv1_15h.20220111.KNU_09_01.PM10.1hsp.2022011121.png
첨부파일명2 https://www.airkorea.or.kr/file/proxyImage?fileName=2022/01/11/AQFv1_15h.20220111.KNU_09_01.PM10.1hsp.2022011203.png
첨부파일명3 https://www.airkorea.or.kr/file/proxyImage?fileName=2022/01/11/AQFv1_15h.20220111.KNU_09_01.PM10.1hsp.2022011209.png
첨부파일명4 https://www.airkorea.or.kr/file/proxyImage?fileName=2022/01/11/AQFv1_15h.20220111.KNU_09_01.PM2P5.1hsp.2022011121.png
첨부파일명5 https://www.airkorea.or.kr/file/proxyImage?fileName=2022/01/11/AQFv1_15h.20220111.KNU_09_01.PM2P5.1hsp.2022011203.png
첨부파일명6 https://www.airkorea.or.kr/file/proxyImage?fileName=2022/01/11/AQFv1_15h.20220111.KNU_09_01.PM2P5.1hsp.2022011209.png
첨부파일명7 https://www.airkorea.or.kr/file/proxyImage?fileName=2022/01/11/AQFv1_15h.20220111.KNU_09_01.PM10.2days.ani.gif
첨부파일명8 https://www.airkorea.or.kr/file/proxyImage?fileName=
첨부파일명9 https://www.airkorea.or.kr/file/proxyImage?fileName=
예측통보시간 2022-01-11
Name: 0, dtype: object데이터를 보면 미세먼지 농도같은 수치형 데이터보다는, 일기예보에서 사용되는 예보 개황을 자연어로 얻을 수 있다
수치형 자료보다는 다음과 같은 이미지 및 애니메이션(GIF)의 URL을 가져올 수 있어서 여러모로 활용도가 높은 서비스 (첨부파일명 각각이 의미하는 바는 API 명세서 참고)
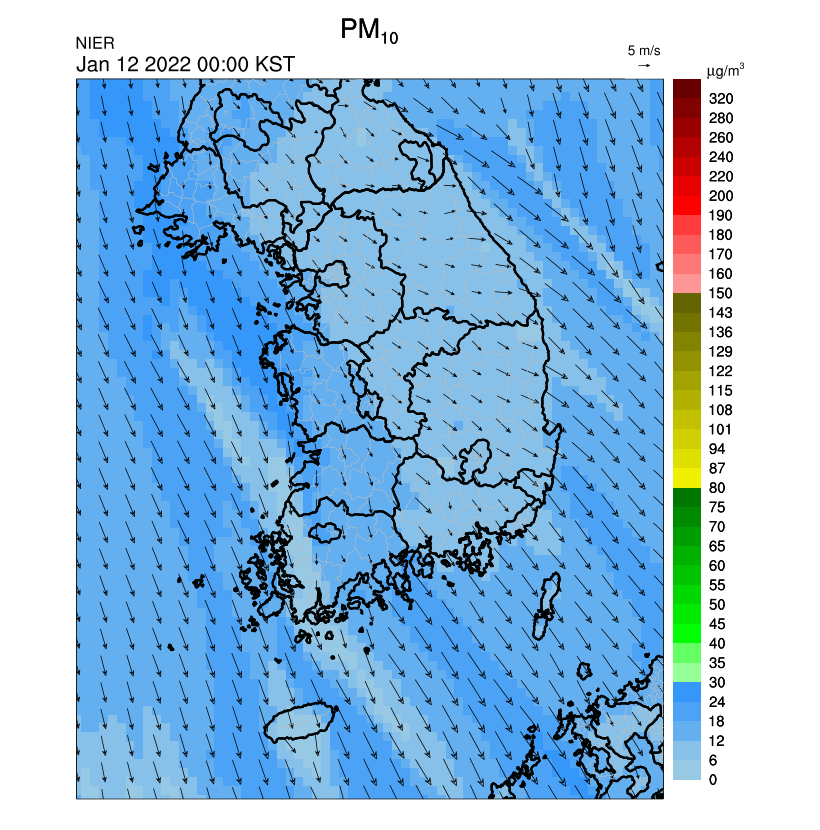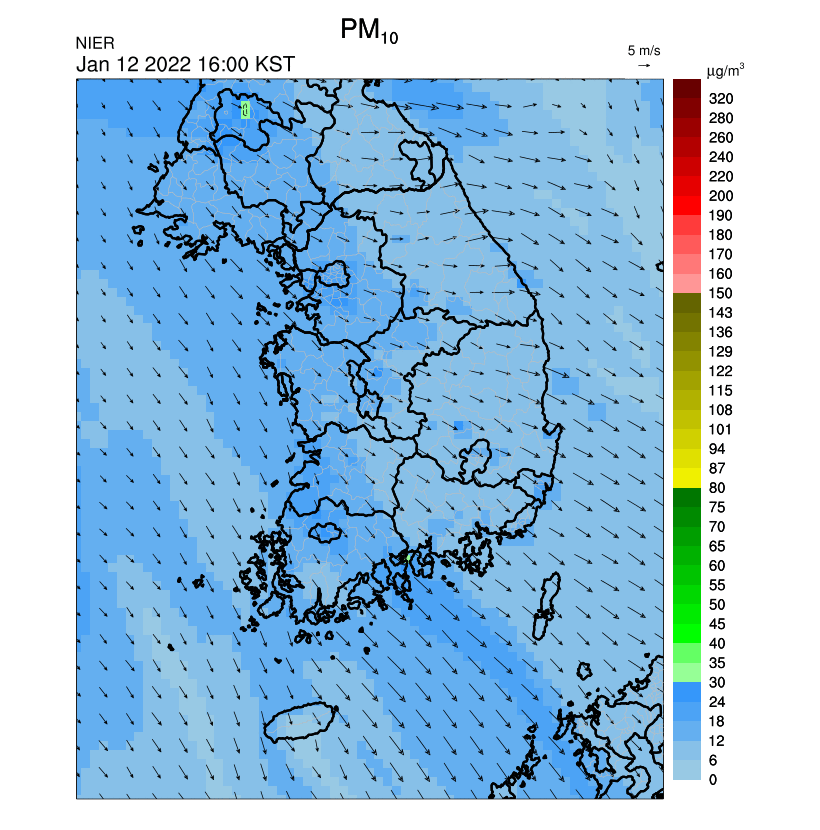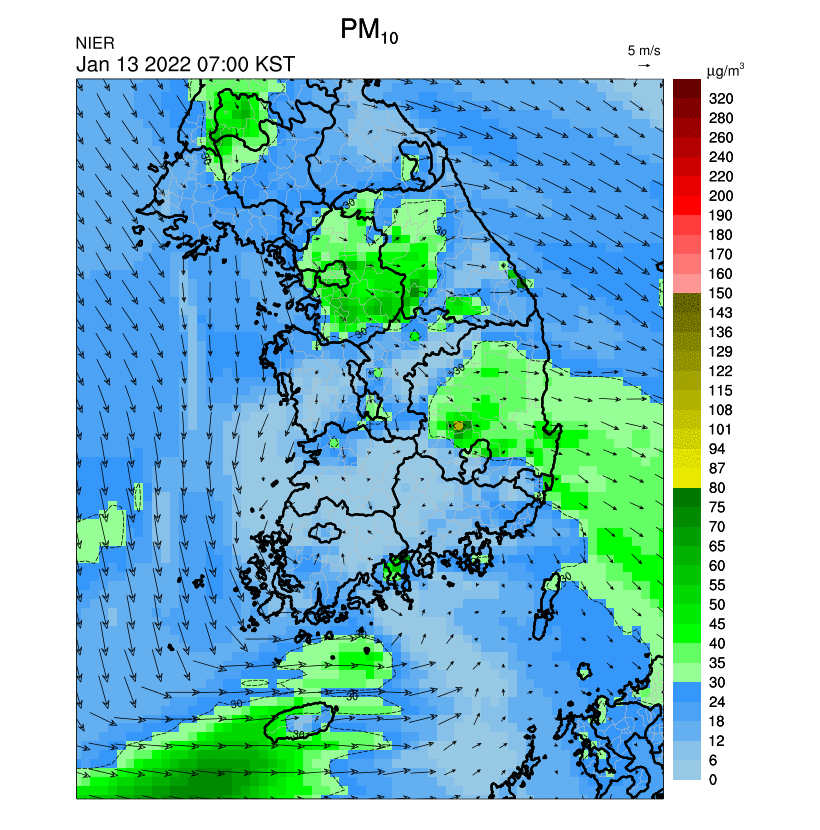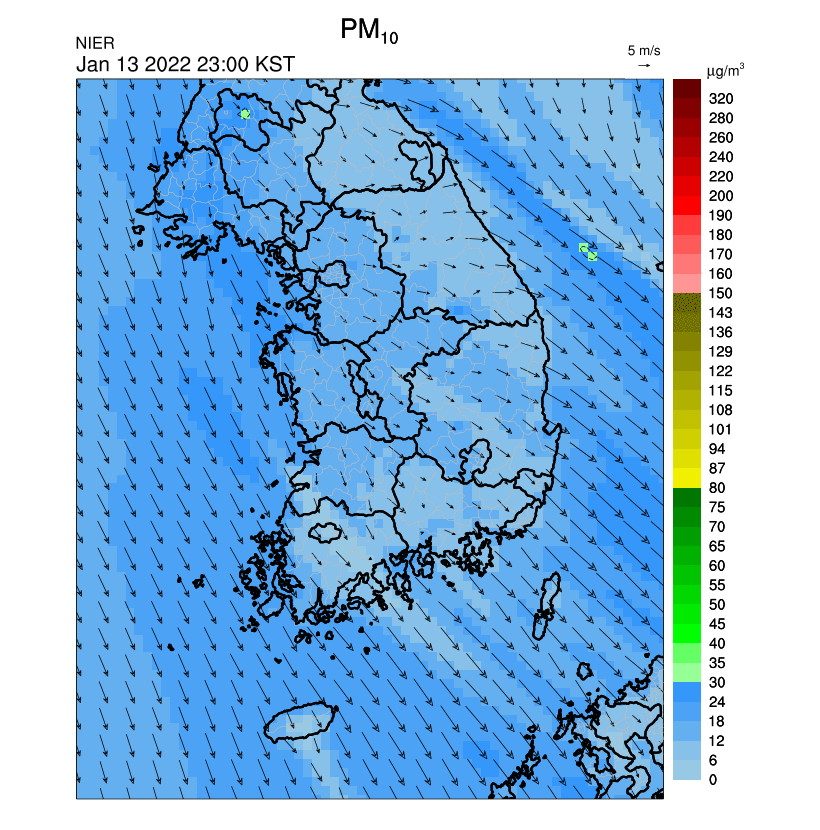
3.2. 초미세먼지 주간예보
상세 URL: getMinuDustWeekFrcstDspth
[필수 파라미터]
없음
[선택(옵션) 파라미터]
searchDate: 조회 날짜 (YYYY-mm-dd 포맷 문자열)
※ 조회날짜 없을 경우 조회 당일 날짜 기준으로 자동으로 세팅된다
마찬가지로 테스트 코드를 만들어보자
[sample_getMinuDustWeekFrcstDspth.py]
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 초미세먼지 주간예보 조회
url_base = "http://apis.data.go.kr/B552584/ArpltnInforInqireSvc"
url_spec = "getMinuDustWeekFrcstDspth"
url = url_base + "/" + url_spec
api_key_utf8 = "Your API Key from data.go.kr"
api_key_decode = requests.utils.unquote(api_key_utf8, encoding='utf-8')
search_date = "2022-01-11"
params = {
"serviceKey": api_key_decode,
"returnType": "xml",
"searchDate": search_date
}
response = requests.get(url, params=params)
if response.status_code == 200:
xml = BeautifulSoup(response.text.replace('\n', ''), "lxml")
items = xml.findAll("item")
item_list = []
for item in items:
item_dict = {
'첫째날예보': convert_string(item, "frcstOneCn"),
'둘째날예보': convert_string(item, "frcstTwoCn"),
'셋째날예보': convert_string(item, "frcstThreeCn"),
'넷째날예보': convert_string(item, "frcstFourCn"),
'발표일시': convert_string(item, "presnatnDt"),
'첫째날예보일시': convert_string(item, "frcstOneDt"),
'둘째날예보일시': convert_string(item, "frcstTwoDt"),
'셋째날예보일시': convert_string(item, "frcstThreeDt"),
'넷째날예보일시': convert_string(item, "frcstFourDt"),
'대기질 전망': convert_string(item, "gwthcnd")
}
item_list.append(item_dict)
df = pd.DataFrame(item_list)초미세먼지 주간예보는 조회 날짜(search_date) 기준 3일 뒤부터 4일간의 예보 정보를 제공한며, 데이터를 1개의 레코드로 구성된다
In [8]: df.shape
Out[8]: (1, 10)In [9]: df.iloc[0]
Out[9]:
첫째날예보 서울 : 낮음, 인천 : 낮음, 경기북부 : 낮음, 경기남부 : 낮음, 강원영서 : 낮음, 강원영동 : 낮음, 대전 : 낮음, 세종 : 낮음, 충남 : 낮음, 충북 : 낮음, 광주 : 낮음, 전북 : 낮음, 전남 : 낮음, 부산 : 낮음, 대구 : 낮음, 울산 : 낮음, 경북 : 낮음, 경남 : 낮음, 제주 : 낮음, 신뢰도 : 보통
둘째날예보 서울 : 낮음, 인천 : 높음, 경기북부 : 낮음, 경기남부 : 높음, 강원영서 : 낮음, 강원영동 : 낮음, 대전 : 낮음, 세종 : 낮음, 충남 : 낮음, 충북 : 낮음, 광주 : 낮음, 전북 : 낮음, 전남 : 낮음, 부산 : 낮음, 대구 : 낮음, 울산 : 낮음, 경북 : 낮음, 경남 : 낮음, 제주 : 낮음, 신뢰도 : 보통
셋째날예보 서울 : 낮음, 인천 : 낮음, 경기북부 : 낮음, 경기남부 : 낮음, 강원영서 : 낮음, 강원영동 : 낮음, 대전 : 낮음, 세종 : 낮음, 충남 : 낮음, 충북 : 높음, 광주 : 낮음, 전북 : 낮음, 전남 : 낮음, 부산 : 낮음, 대구 : 낮음, 울산 : 낮음, 경북 : 낮음, 경남 : 낮음, 제주 : 낮음, 신뢰도 : 낮음
넷째날예보 서울 : 낮음, 인천 : 낮음, 경기북부 : 낮음, 경기남부 : 낮음, 강원영서 : 낮음, 강원영동 : 낮음, 대전 : 낮음, 세종 : 낮음, 충남 : 낮음, 충북 : 낮음, 광주 : 낮음, 전북 : 낮음, 전남 : 낮음, 부산 : 낮음, 대구 : 낮음, 울산 : 낮음, 경북 : 낮음, 경남 : 낮음, 제주 : 낮음, 신뢰도 : 낮음
발표일시 2022-01-11
첫째날예보일시 2022-01-14
둘째날예보일시 2022-01-15
셋째날예보일시 2022-01-16
넷째날예보일시 2022-01-17
대기질 전망 1월 15일 전일 잔류한 미세먼지와 국외 유입으로 인하여 인천·경기남부 '높음', 16일 대기 정체로 인하여 충북 '높음'일 것으로 예상됩니다. 그 밖의 날은 원활한 대기 확산으로 전 권역 '낮음'일 것으로 예상됩니다.
Name: 0, dtype: object각 지역별로 \(PM_{2.5}\) 농도가 \(0 \~ 35\mu g/m^{3}\)이면 '낮음', \(36\mu g/m^{3}\) 이상이면 '높음'으로 표기된다
범주형 데이터이니 활용도가 그닥 높지는 않다
3.3. 측정소별 실시간 측정정보
상세 URL: getMsrstnAcctoRltmMesureDnsty
[필수 파라미터]
stationName: 측정소명 (측정소 이름을 정확히 기입해야 한다, ex: "광교동")
dataTerm: 데이터기간 (1일 = "DAILY", 1개월 = "MONTH", 3개월 = "3MONTH")
[선택(옵션) 파라미터]
ver: 오퍼레이션 버전 ("1.0", "1.1", "1.2", "1.3")
<오퍼레이션 버전>
파라미터 기입하지 않을 경우 : \(PM_{2.5}\) 데이터 제외된 결과 반환
1.0 : \(PM_{2.5}\) 데이터 포함된 결과 반환
1.1 : \(PM_{10}\), \(PM_{2.5}\) 의 "예측이동 평균데이터" 포함 결과 반환
1.2 : "측정망 정보 데이터" 포함된 결과 반환
1.3 : \(PM_{10}\), \(PM_{2.5}\) 의 "1시간 등급 자료" 포함 결과 반환
측정소명은 API 명세서에서는 찾아볼 수 없고, 에어코리아 웹페이지에서 조회할 수 있다
https://airkorea.or.kr/web/stationInfo?pMENU_NO=93
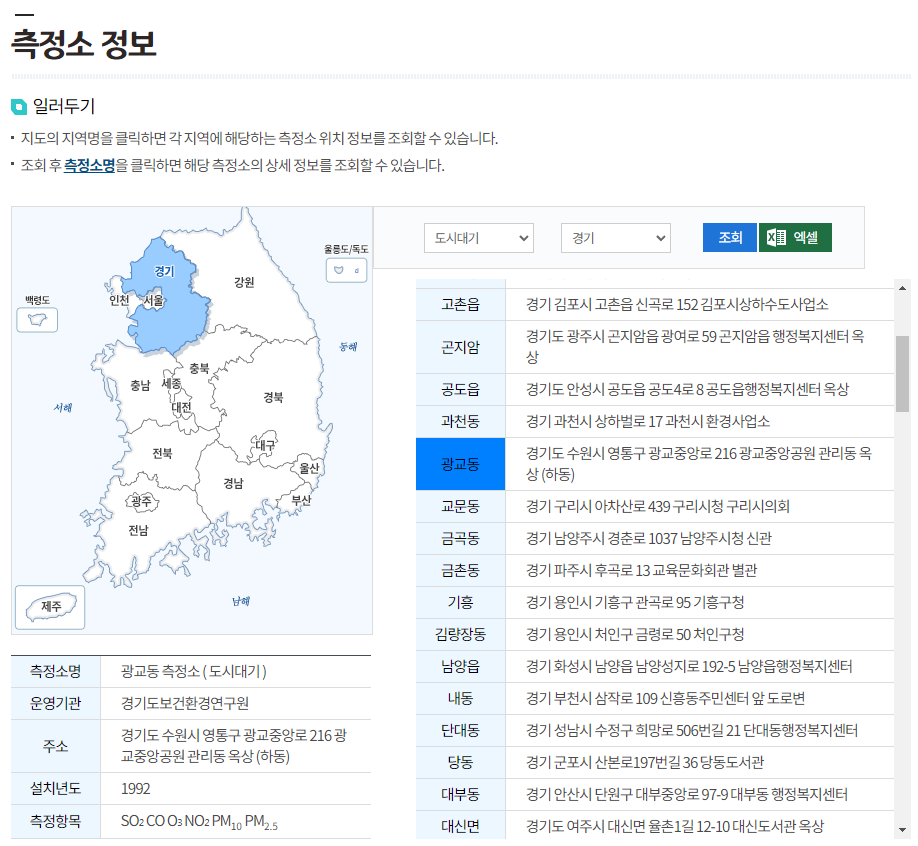
대분류로 국가배경/교외대기/도시대기/도로변대기/항만, 그리고 지역별로 조회할 수 있는데, 측정소가 상당히 많기 때문에 전국 측정소별 현황 등을 서비스하고자 할 경우 운영계정으로 변경할 필요가 있다
- 다음 기회에 측정소 리스트를 크롤링해보자
[sample_getMsrstnAcctoRltmMesureDnsty.py]
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 측정소별 실시간 측정정보 조회
url_base = "http://apis.data.go.kr/B552584/ArpltnInforInqireSvc"
url_spec = "getMsrstnAcctoRltmMesureDnsty"
url = url_base + "/" + url_spec
api_key_utf8 = "Your API Key from data.go.kr"
api_key_decode = requests.utils.unquote(api_key_utf8, encoding='utf-8')
params = {
"serviceKey": api_key_decode,
"returnType": "xml",
"stationName": "광교동",
"dataTerm": "DAILY",
"ver": "1.3",
"numOfRows": 100000,
"pageNo": 1
}
response = requests.get(url, params=params)
print(f"<Response Code: {response.status_code}>")
if response.status_code == 200:
xml = BeautifulSoup(response.text.replace('\n', ''), "lxml")
items = xml.findAll("item")
item_list = []
for item in items:
item_dict = {
'측정일': convert_string(item, "dataTime"),
'측정망 정보': convert_string(item, "mangName"),
'아황산가스 농도': convert_string(item, "so2Value"),
'일산화탄소 농도': convert_string(item, "coValue"),
'오존 농도': convert_string(item, "o3Value"),
'이산화질소 농도': convert_string(item, "no2Value"),
'미세먼지(PM10) 농도': convert_string(item, "pm10Value"),
'미세먼지(PM10) 24시간 예측이동농도': convert_string(item, "pm10Value24"),
'초미세먼지(PM2.5) 농도': convert_string(item, "pm25Value"),
'초미세먼지(PM2.5) 24시간 예측이동농도': convert_string(item, "pm25Value24"),
'통합대기환경수치': convert_string(item, "khaiValue"),
'통합대기환경지수': convert_string(item, "khaiGrade"),
'아황산가스 지수': convert_string(item, "so2Grade"),
'일산화탄소 지수': convert_string(item, "coGrade"),
'오존 지수': convert_string(item, "o3Grade"),
'이산화질소 지수': convert_string(item, "no2Grade"),
'미세먼지(PM10) 24시간 등급': convert_string(item, "pm10Grade"),
'초미세먼지(PM2.5) 24시간 등급': convert_string(item, "pm25Grade"),
'미세먼지(PM10) 1시간 등급': convert_string(item, "pm10Grade1h"),
'초미세먼지(PM2.5) 1시간 등급': convert_string(item, "pm25Grade1h"),
'아황산가스 플래그': convert_string(item, "so2Flag"),
'일산화탄소 플래그': convert_string(item, "coFlag"),
'오존 플래그': convert_string(item, "o3Flag"),
'이산화질소 플래그': convert_string(item, "no2Flag"),
'미세먼지(PM10) 플래그': convert_string(item, "pm10Flag"),
'초미세먼지(PM2.5) 플래그': convert_string(item, "pm25Flag"),
}
item_list.append(item_dict)
df = pd.DataFrame(item_list)조회하는 시간을 시점으로 하루, 1달, 3달의 측정데이터를 반환하며, 측정은 1시간 단위로 이뤄진다
아황산가스, 일산화탄소, 오존, 이산화질소, 미세먼지, 초미세먼지 6개 항목에 대한 농도 수치 자료와 통합대기환경수치 및 지수, 미세먼지 등급을 제공하므로 가장 유용하게 활용할 수 있다
2022년 1월 12일 오전 11시 30분에 호출하면 결과는 다음과 같다
In [9]: df.shape
Out[9]: (23, 26)
In [10]: df['측정일']
Out[10]:
0 2022-01-12 11:00
1 2022-01-12 10:00
2 2022-01-12 09:00
3 2022-01-12 08:00
4 2022-01-12 07:00
5 2022-01-12 06:00
6 2022-01-12 05:00
7 2022-01-12 04:00
8 2022-01-12 03:00
9 2022-01-12 02:00
10 2022-01-12 01:00
11 2022-01-11 24:00
12 2022-01-11 23:00
13 2022-01-11 22:00
14 2022-01-11 21:00
15 2022-01-11 20:00
16 2022-01-11 19:00
17 2022-01-11 18:00
18 2022-01-11 17:00
19 2022-01-11 16:00
20 2022-01-11 15:00
21 2022-01-11 14:00
22 2022-01-11 13:00
Name: 측정일, dtype: object만약 한달치 데이터를 얻고 싶으면
params = {
"serviceKey": api_key_decode,
"returnType": "xml",
"stationName": "광교동",
"dataTerm": "MONTH",
"ver": "1.3",
"numOfRows": 100000,
"pageNo": 1
}와 같이 파라미터 설정 후 호출하면
In [11]: df.shape
Out[11]: (740, 26)
In [12]: df['측정일'].iloc[0]
Out[12]: '2022-01-12 11:00'
In [13]: df['측정일'].iloc[-1]
Out[13]: '2021-12-12 13:00'하루 최대 24개 레코드가 담긴 한달치 데이터 (720개 혹은 744개 + 오늘 데이터)를 한꺼번에 얻을 수 있다
In [14]: df.iloc[0]
Out[14]:
측정일 2022-01-12 11:00
측정망 정보 도시대기
아황산가스 농도 0.003
일산화탄소 농도 0.7
오존 농도 0.014
이산화질소 농도 0.025
미세먼지(PM10) 농도 32
미세먼지(PM10) 24시간 예측이동농도 27
초미세먼지(PM2.5) 농도 18
초미세먼지(PM2.5) 24시간 예측이동농도 14
통합대기환경수치 47
통합대기환경지수 1
아황산가스 지수 1
일산화탄소 지수 1
오존 지수 1
이산화질소 지수 1
미세먼지(PM10) 24시간 등급 1
초미세먼지(PM2.5) 24시간 등급 1
미세먼지(PM10) 1시간 등급 2
초미세먼지(PM2.5) 1시간 등급 2
아황산가스 플래그
일산화탄소 플래그
오존 플래그
이산화질소 플래그
미세먼지(PM10) 플래그
초미세먼지(PM2.5) 플래그
Name: 0, dtype: object농도 단위는 앞에서 이야기했고, 지수는 "1:좋음, 2:보통, 3:나쁨, 4:매우나쁨"을 가리키며, 플래그는 측정소의 장비 상태가 "점검 및 교정, 장비 점검, 자료 이상, 통신 장애"에 해당되는지 여부를 가리킨다 (Nan이면 정상 상태)
예상이 아니라 조회 시점 기준 최대 59분 이전의 자료가 최신이기 때문에 약간 아쉽긴 하지만, 그래도 수치형으로 얻을 수 있을 뿐만 아니라 최대 3달간의 자료를 얻을 수 있으므로 요긴하게 사용할 수 있다
가장 최신 데이터만 얻고 싶다면
params = {
"serviceKey": api_key_decode,
"returnType": "xml",
"stationName": "광교동",
"dataTerm": "DAILY",
"ver": "1.3",
"numOfRows": 1,
"pageNo": 1
}와 같이 파라미터를 설정하면 빠르게 조회할 수 있다
3.4. 통합대기환경지수 나쁨 이상 측정소 목록
상세 URL: getUnityAirEnvrnIdexSnstiveAboveMsrstnList
[필수 파라미터]
없음
[선택(옵션) 파라미터]
없음
전체 측정소 중 '통합대기환경지수'가 나쁨 이상으로 측정된 측정소의 이름과 주소만 반환한다
통합대기환경지수가 무엇인고 하니...


음! 복잡하다! 그냥 그런가보다~~ 하는게 속이 편하다

나쁨 이상이면 좋지 않다! 정도로만 알고 있자...
[sample_getUnityAirEnvrnIdexSnstiveAboveMsrstnList.py]
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 통합대기환경지수 나쁨 이상 측정소 목록 조회
url_base = "http://apis.data.go.kr/B552584/ArpltnInforInqireSvc"
url_spec = "getUnityAirEnvrnIdexSnstiveAboveMsrstnList"
url = url_base + "/" + url_spec
api_key_utf8 = "Your API Key from data.go.kr"
api_key_decode = requests.utils.unquote(api_key_utf8, encoding='utf-8')
params = {
"serviceKey": api_key_decode,
"returnType": "xml",
"numOfRows": 999999
}
response = requests.get(url, params=params)
if response.status_code == 200:
xml = BeautifulSoup(response.text.replace('\n', ''), "lxml")
items = xml.findAll("item")
item_list = []
for item in items:
item_dict = {
'측정소명': convert_string(item, "stationName"),
'측정소 주소': convert_string(item, "addr")
}
item_list.append(item_dict)
df = pd.DataFrame(item_list)2022월 12일 오후 12시 기준 조회 결과는
In [14]: df
Out[14]:
측정소명 측정소 주소
0 선단동 경기 포천시 삼육사로 2186번길 11-15선단보건지소
1 운암면 전북 임실군 운암면 선거리51-10단 2군데만 조회되었다 (미세먼지없는 말끔한 날인가보다 ㅎㅎ)
실시간 조회밖에 안되기때문에 이것도 그닥 유용해보이진 않는다 (웹서비스할때는 팝업 띄우는 정도로?)
3.5. 시도별 실시간 측정정보
상세 URL: getCtprvnRltmMesureDnsty
[필수 파라미터]
sidoName: 시/도명, 시도명은 다음 문자열 중 선택
<전국, 서울, 부산, 대구, 인천, 광주, 대전, 울산, 경기, 강원, 충북, 충남, 전북, 전남, 경북, 경남, 제주, 세종>
[선택(옵션) 파라미터]
ver: 오퍼레이션 버전 ("1.0", "1.1", "1.2", "1.3"), 3.3 설명 참고
[sample_getCtprvnRltmMesureDnsty.py]
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 시도별 실시간 측정정
url_base = "http://apis.data.go.kr/B552584/ArpltnInforInqireSvc"
url_spec = "getCtprvnRltmMesureDnsty"
url = url_base + "/" + url_spec
api_key_utf8 = "Your API Key from data.go.kr"
api_key_decode = requests.utils.unquote(api_key_utf8, encoding='utf-8')
params = {
"serviceKey": api_key_decode,
"returnType": "xml",
"numOfRows": 999999,
"sidoName": "경기",
"ver": "1.3"
}
response = requests.get(url, params=params)
if response.status_code == 200:
xml = BeautifulSoup(response.text.replace('\n', ''), "lxml")
items = xml.findAll("item")
item_list = []
for item in items:
item_dict = {
'측정소명': convert_string(item, "stationName"),
'측정망 정보': convert_string(item, "mangName"),
'시도명': convert_string(item, "sidoName"),
'측정일시': convert_string(item, "dataTime"),
'아황산가스 농도': convert_string(item, "so2Value"),
'일산화탄소 농도': convert_string(item, "coValue"),
'오존 농도': convert_string(item, "o3Value"),
'이산화질소 농도': convert_string(item, "no2Value"),
'미세먼지(PM10) 농도': convert_string(item, "pm10Value"),
'미세먼지(PM10) 24시간 예측이동농도': convert_string(item, "pm10Value24"),
'초미세먼지(PM2.5) 농도': convert_string(item, "pm25Value"),
'초미세먼지(PM2.5) 24시간 예측이동농도': convert_string(item, "pm25Value24"),
'통합대기환경수치': convert_string(item, "khaiValue"),
'통합대기환경지수': convert_string(item, "khaiGrade"),
'아황산가스 지수': convert_string(item, "so2Grade"),
'일산화탄소 지수': convert_string(item, "coGrade"),
'오존 지수': convert_string(item, "o3Grade"),
'이산화질소 지수': convert_string(item, "no2Grade"),
'미세먼지(PM10) 24시간 등급': convert_string(item, "pm10Grade"),
'초미세먼지(PM2.5) 24시간 등급': convert_string(item, "pm25Grade"),
'미세먼지(PM10) 1시간 등급': convert_string(item, "pm10Grade1h"),
'초미세먼지(PM2.5) 1시간 등급': convert_string(item, "pm25Grade1h"),
'아황산가스 플래그': convert_string(item, "so2Flag"),
'일산화탄소 플래그': convert_string(item, "coFlag"),
'오존 플래그': convert_string(item, "o3Flag"),
'이산화질소 플래그': convert_string(item, "no2Flag"),
'미세먼지(PM10) 플래그': convert_string(item, "pm10Flag"),
'초미세먼지(PM2.5) 플래그': convert_string(item, "pm25Flag"),
}
item_list.append(item_dict)
df = pd.DataFrame(item_list)2022년 1월 12일 기준 '경기' 지역에서는 총 124개 도시/도로 측정소의 결과를 반환한다
In [15]: df.shape
Out[15]: (124, 28)'시도명'이 추가된 것 말고는 측정소별 실시간 측정정보와 반환하는 데이터 종류는 동일하다
In [16]: df[df['측정소명'] == '연천'].iloc[0]
Out[16]:
측정소명 연천
측정망 정보 도시대기
시도명 경기
측정일시
아황산가스 농도
일산화탄소 농도
오존 농도
이산화질소 농도
미세먼지(PM10) 농도
미세먼지(PM10) 24시간 예측이동농도
초미세먼지(PM2.5) 농도
초미세먼지(PM2.5) 24시간 예측이동농도
통합대기환경수치
통합대기환경지수
아황산가스 지수
일산화탄소 지수
오존 지수
이산화질소 지수
미세먼지(PM10) 24시간 등급
초미세먼지(PM2.5) 24시간 등급
미세먼지(PM10) 1시간 등급
초미세먼지(PM2.5) 1시간 등급
아황산가스 플래그 통신장애
일산화탄소 플래그 통신장애
오존 플래그 통신장애
이산화질소 플래그 통신장애
미세먼지(PM10) 플래그 통신장애
초미세먼지(PM2.5) 플래그 통신장애
Name: 14, dtype: object'연천'의 경우 모든 플래그에 '통신장애'가 떠서 데이터가 들어오지 못하고 있다 ㅎㅎ
이것 또한 실시간 최신 데이터만 반영하기 때문에, 각 측정소 주소와 연동하여 대한민국 전도에 측정소별 결과를 다음과 같이 꾸며서 서비스할 수 있다
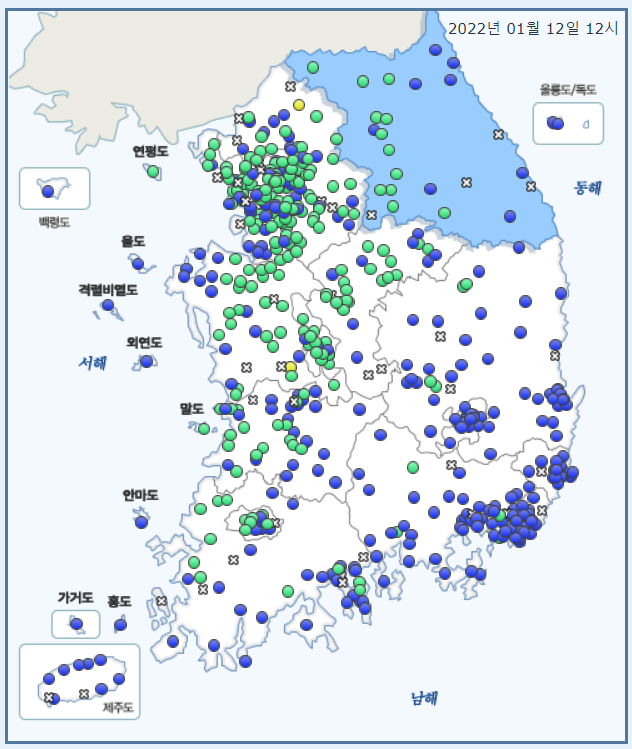
바로 다음 포스트 글에서 위와 같이 지도시각화하는 예시를 만들어볼까 한다 ㅎㅎ
4. 클래스 작성
상세항목 5개 개별로 함수를 만들어도 되지만, 클래스 하나로 구현하는 것도 나쁘지 않은 선택인 것 같아 한 번 만들어봤다
import requests
import datetime
import pandas as pd
from typing import Union
from bs4 import BeautifulSoup, element
class AirQuality:
def __init__(self):
api_key_utf8 = "Your API Key from data.go.kr"
self._api_key = requests.utils.unquote(api_key_utf8, encoding='utf-8')
self._url_base = "http://apis.data.go.kr/B552584/ArpltnInforInqireSvc"
@staticmethod
def _convert_tag_string(item_: element.Tag, key_: str):
try:
return item_.find(key_.lower()).text.strip()
except AttributeError:
return None
def _getDataFrameCommon(self, service_url: str, params: dict, parse_info: dict, change_header_name: bool = True) -> pd.DataFrame:
"""
response - xml - dataframe 변환 공통 메서드
"""
url = self._url_base + "/" + service_url
params['serviceKey'] = self._api_key
params['returnType'] = "xml"
params['numOfRows'] = 999999
print(f"Try to request service - {service_url}")
response = requests.get(url, params=params)
print(f"GET Response Status: {response.status_code}")
if response.status_code == 200:
xml = BeautifulSoup(response.text, "lxml")
resultcode = xml.find("resultcode").text
resultmsg = xml.find("resultmsg").text
print(f"Result: {resultmsg}({resultcode})")
totalcount = int(xml.find("totalcount").text)
print(f"Total Count: {totalcount}")
items = xml.findAll("item")
item_list = []
for item in items:
# 파싱되지 않는 태그 있는지 여부 검색 후 출력
tag_names = [x.name for x in list(item)]
keys = [x.lower() for x in parse_info.keys()]
unparsed = list(filter(lambda x: x not in keys and x is not None, tag_names))
if len(unparsed) > 0:
print(f"Warning: parse info missing - {unparsed}")
# 딕셔너리로 파싱
item_dict = {}
for key, value in parse_info.items():
if change_header_name:
item_dict[value] = self._convert_tag_string(item, key)
else:
item_dict[key] = self._convert_tag_string(item, key)
item_list.append(item_dict)
return pd.DataFrame(item_list)
else:
return pd.DataFrame()
def getAirQualityPrediction(self, target_date: Union[datetime.date, str] = None, change_header_name: bool = True) -> pd.DataFrame:
"""
대기질 예보통보 조회
"""
if target_date is None:
search_date = datetime.datetime.now().strftime("%Y-%m-%d")
else:
if isinstance(target_date, datetime.date):
search_date = target_date.strftime("%Y-%m-%d")
else:
search_date = str(target_date)
params = {
"searchDate": search_date,
"ver": "1.1"
}
parser_info = {
"dataTime": "통보시간",
"informCode": "통보코드",
"informOverall": "예보개황",
"informCause": "발생원인",
"informGrade": "예보등급",
"actionKnack": "행동요령",
"imageUrl1": "첨부파일명1",
"imageUrl2": "첨부파일명2",
"imageUrl3": "첨부파일명3",
"imageUrl4": "첨부파일명4",
"imageUrl5": "첨부파일명5",
"imageUrl6": "첨부파일명6",
"imageUrl7": "첨부파일명7",
"imageUrl8": "첨부파일명8",
"imageUrl9": "첨부파일명9",
"informData": "예측통보시간"
}
return self._getDataFrameCommon('getMinuDustFrcstDspth', params, parser_info, change_header_name)
def getCurrentBadAirObservatoryInfo(self, change_header_name: bool = True):
"""
통합대기환경지수 나쁨 이상 측정소 목록 조회
"""
params = {}
parser_info = {
"stationName": "측정소명",
"addr": "측정소 주소",
}
return self._getDataFrameCommon('getUnityAirEnvrnIdexSnstiveAboveMsrstnList', params, parser_info, change_header_name)
def getWeeklyDustPredict(self, target_date: Union[datetime.date, str] = None, change_header_name: bool = True) -> pd.DataFrame:
"""
초미세먼지 주간예보 조회
"""
if target_date is None:
search_date = datetime.datetime.now().strftime("%Y-%m-%d")
else:
if isinstance(target_date, datetime.date):
search_date = target_date.strftime("%Y-%m-%d")
else:
search_date = str(target_date)
params = {
"searchDate": search_date
}
parser_info = {
"frcstOneCn": "첫째날예보",
"frcstTwoCn": "둘째날예보",
"frcstThreeCn": "셋째날예보",
"frcstFourCn": "넷째날예보",
"presnatnDt": "발표일시",
"frcstOneDt": "첫째날예보일시",
"frcstTwoDt": "둘째날예보일시",
"frcstThreeDt": "셋째날예보일시",
"frcstFourDt": "넷째날예보일시",
"gwthcnd": "대기질 전망"
}
return self._getDataFrameCommon('getMinuDustWeekFrcstDspth', params, parser_info, change_header_name)
def getObservatoryMeasurement(self, obs_name: str, duration_day: int = 1, change_header_name: bool = True):
"""
측정소별 실시간 측정정보 조회
"""
if duration_day < 2:
dataTerm = "DAILY"
elif duration_day <= 31:
dataTerm = "MONTH"
else:
dataTerm = "3MONTH"
params = {
"stationName": obs_name,
"dataTerm": dataTerm,
"ver": "1.3"
}
parser_info = {
"dataTime": "측정일",
"mangName": "측정망 정보",
"so2Value": "아황산가스 농도",
"coValue": "일산화탄소 농도",
"o3Value": "오존 농도",
"no2Value": "이산화질소 농도",
"pm10Value": "미세먼지(PM10) 농도",
"pm10Value24": "미세먼지(PM10) 24시간 예측이동농도",
"pm25Value": "초미세먼지(PM2.5) 농도",
"pm25Value24": "초미세먼지(PM2.5) 24시간 예측이동농도",
"khaiValue": "통합대기환경수치",
"khaiGrade": "통합대기환경지수",
"so2Grade": "아황산가스 지수",
"coGrade": "일산화탄소 지수",
"o3Grade": "오존 지수",
"no2Grade": "이산화질소 지수",
"pm10Grade": "미세먼지(PM10) 24시간 등급",
"pm25Grade": "초미세먼지(PM2.5) 24시간 등급",
"pm10Grade1h": "미세먼지(PM10) 1시간 등급",
"pm25Grade1h": "초미세먼지(PM2.5) 1시간 등급",
"so2Flag": "아황산가스 플래그",
"coFlag": "일산화탄소 플래그",
"o3Flag": "오존 플래그",
"no2Flag": "이산화질소 플래그",
"pm10Flag": "미세먼지(PM10) 플래그",
"pm25Flag": "초미세먼지(PM2.5) 플래그"
}
return self._getDataFrameCommon('getMsrstnAcctoRltmMesureDnsty', params, parser_info, change_header_name)
def getCityMeasurement(self, name: str, change_header_name: bool = True):
"""
시도별 실시간 측정정보
"""
params = {
"sidoName": name,
"ver": "1.3"
}
parser_info = {
"stationName": "측정소명",
"mangName": "측정망 정보",
"sidoName": "시도명",
"dataTime": "측정일시",
"so2Value": "아황산가스 농도",
"coValue": "일산화탄소 농도",
"o3Value": "오존 농도",
"no2Value": "이산화질소 농도",
"pm10Value": "미세먼지(PM10) 농도",
"pm10Value24": "미세먼지(PM10) 24시간 예측이동농도",
"pm25Value": "초미세먼지(PM2.5) 농도",
"pm25Value24": "초미세먼지(PM2.5) 24시간 예측이동농도",
"khaiValue": "통합대기환경수치",
"khaiGrade": "통합대기환경지수",
"so2Grade": "아황산가스 지수",
"coGrade": "일산화탄소 지수",
"o3Grade": "오존 지수",
"no2Grade": "이산화질소 지수",
"pm10Grade": "미세먼지(PM10) 24시간 등급",
"pm25Grade": "초미세먼지(PM2.5) 24시간 등급",
"pm10Grade1h": "미세먼지(PM10) 1시간 등급",
"pm25Grade1h": "초미세먼지(PM2.5) 1시간 등급",
"so2Flag": "아황산가스 플래그",
"coFlag": "일산화탄소 플래그",
"o3Flag": "오존 플래그",
"no2Flag": "이산화질소 플래그",
"pm10Flag": "미세먼지(PM10) 플래그",
"pm25Flag": "초미세먼지(PM2.5) 플래그"
}
return self._getDataFrameCommon('getCtprvnRltmMesureDnsty', params, parser_info, change_header_name)다음과 같이 간단하게 호출해서 사용하면 된다
함수 이름 영어로 짓는게 너무 어렵다 ㅋㅋ
obj = AirQuality()
df1 = obj.getAirQualityPrediction("2022-01-12")
df2 = obj.getCurrentBadAirObservatoryInfo()
df3 = obj.getWeeklyDustPredict("2022-01-11")
df4 = obj.getObservatoryMeasurement("광교동", 1)
df5 = obj.getCityMeasurement("서울")끝~!
[참고]
https://ko.wikipedia.org/wiki/%EB%AF%B8%EC%84%B8%EB%A8%BC%EC%A7%80
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=thstnr82&logNo=220045762215
'Data Analysis > Data Engineering' 카테고리의 다른 글
| 데이터시각화::코로나19 누적확진자 1,000만명 돌파 (0) | 2022.03.24 |
|---|---|
| 웹크롤링 - 한국환경공단(에어코리아) 측정소 정보 가져오기 (0) | 2022.01.13 |
| 웹크롤링 - DART 기업개황 업종별 기업 리스트 가져오기 (Final) (0) | 2022.01.08 |
| 웹크롤링 - DART 기업개황 업종별 기업 리스트 가져오기 (3) (0) | 2022.01.08 |
| 웹크롤링 - DART 기업개황 업종별 기업 리스트 가져오기 (2) (0) | 2022.01.07 |



