
YOGYUI
금융감독원::DART 공시문서 js 렌더링된 HTML 가져오기 본문

배경 설명을 하자면 너무 길어지니 방법론에 대해서만 기술하도록 한다
URL request 후 javascript가 렌더링된 결과를 얻기 위해 requests-HTML 라이브러리를 사용한다
https://docs.python-requests.org/projects/requests-html
requests-HTML v0.3.4 documentation
Requests-HTML: HTML Parsing for Humans (writing Python 3)! This library intends to make parsing HTML (e.g. scraping the web) as simple and intuitive as possible. When using this library you automatically get: Full JavaScript support! CSS Selectors (a.k.a j
docs.python-requests.org

예를 들기 위해 지난 2021년 8월 17일에 공시된 삼성전자(dart코드=00126380, 증권코드=005930)의 반기보고서 (문서번호=20210817001416)를 가져와보자
import time
from requests_html import HTMLSession
rcpNo = '20210817001416'
url_doc = 'https://dart.fss.or.kr/dsaf001/main.do?rcpNo={}'.format(rcpNo)
session = HTMLSession()
response = session.get(url_doc)
# javascript rendering
tm_start = time.perf_counter()
response.html.render()
elapsed = time.perf_counter() - tm_start
session.close()In [1]: elapsed
Out[1]: 2.082205299999714내 PC 환경에서는 렌더링하는데 2초정도 소요된다
※ requests-HTML은 코루틴(coroutine)도 지원하니 실제 어플리케이션으로 구현할 때 참고
DART 보고서에서 실제 문서가 자바스크립트에 의해 렌더링되는 부분은 <iframe id="ifram" ...> 태그다
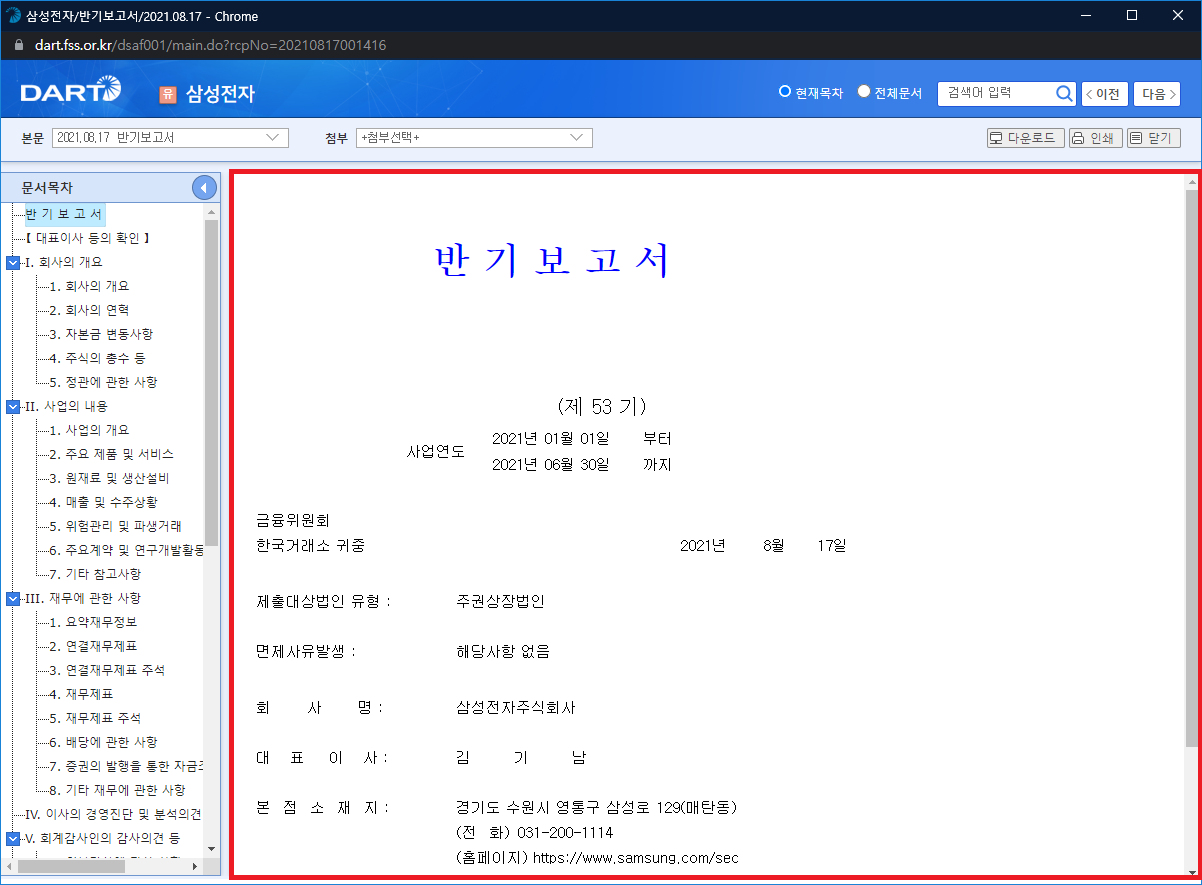
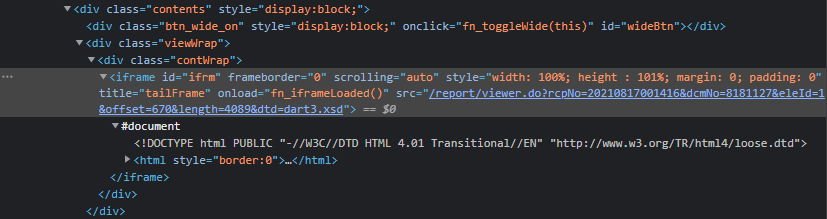
여기서 중요한 건 src 속성이다
구글링해보니 대부분 src 속성에서 dcmNo 값을 크롤링을 통해 알 방법이 없어서 막혔다고 하는데, requests, urllib 등 일반적으로 사용하는 라이브러리로는 자바스크립트 호출 완료 전까지만 결과를 알 수 있기 때문에 iframe 태그에 src 속성이 추가된 것을 확인할 수 없기 때문이다 (렌더링이 중요하다)
requests-HTML 라이브러리는 렌더링 후 html을 확인할 수 있으며, lxml 객체도 제공하기 때문에 다음과 같이 쉽게 태그를 검색할 수 있다
In [2]: response.html.lxml.get_element_by_id("ifrm")
Out[2]: Element iframe at 0x1cf7c3a0680>src 속성도 가져와보자
src = response.html.lxml.get_element_by_id("ifrm").attrib.get('src')In [3]: src
Out[3]: '/report/viewer.do?rcpNo=20210817001416&dcmNo=8181127&eleId=1&offset=670&length=4089&dtd=dart3.xsd'
src url은 dart url(https://dart.fss.or.kr)과 결합하면 원문을 가져올 수 있다
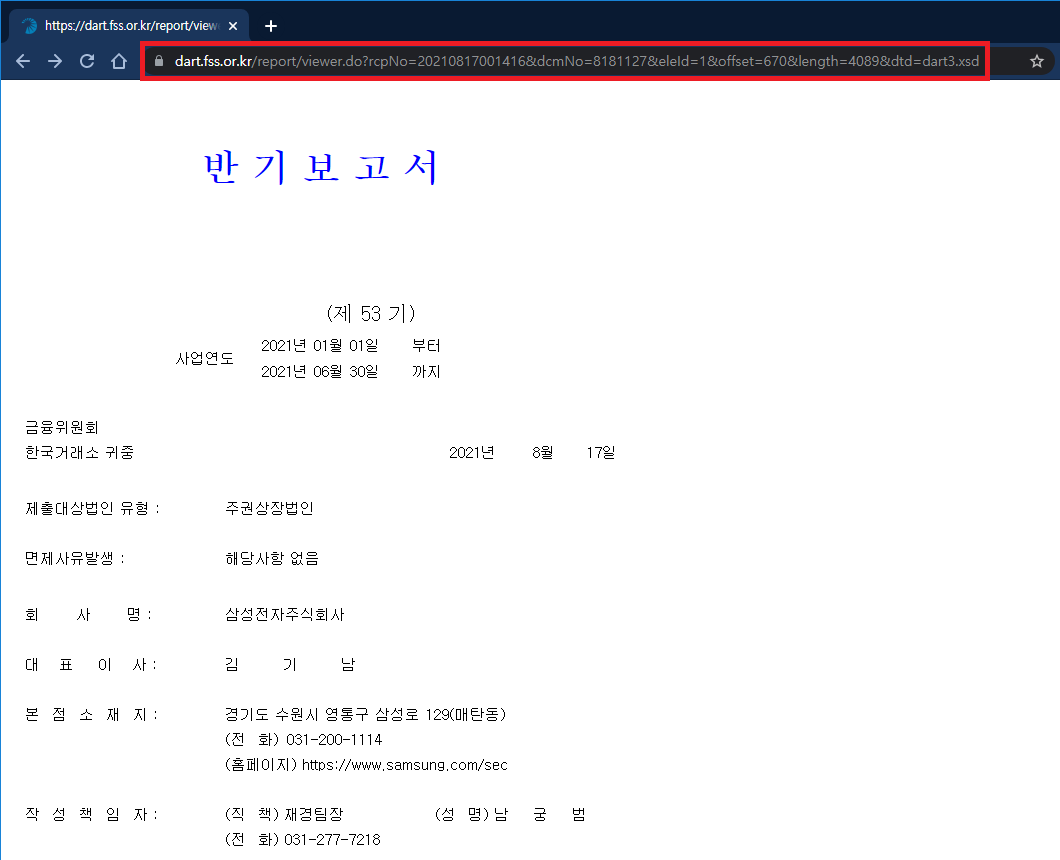
이 때, 호출 인자 중 offset과 length가 670, 4089로 설정되어 있어 첫번째 페이지만 렌더링되는 문제가 있는데, 모두 0으로 바꾸고 다시 호출하면 전체 문서를 가져올 수 있다
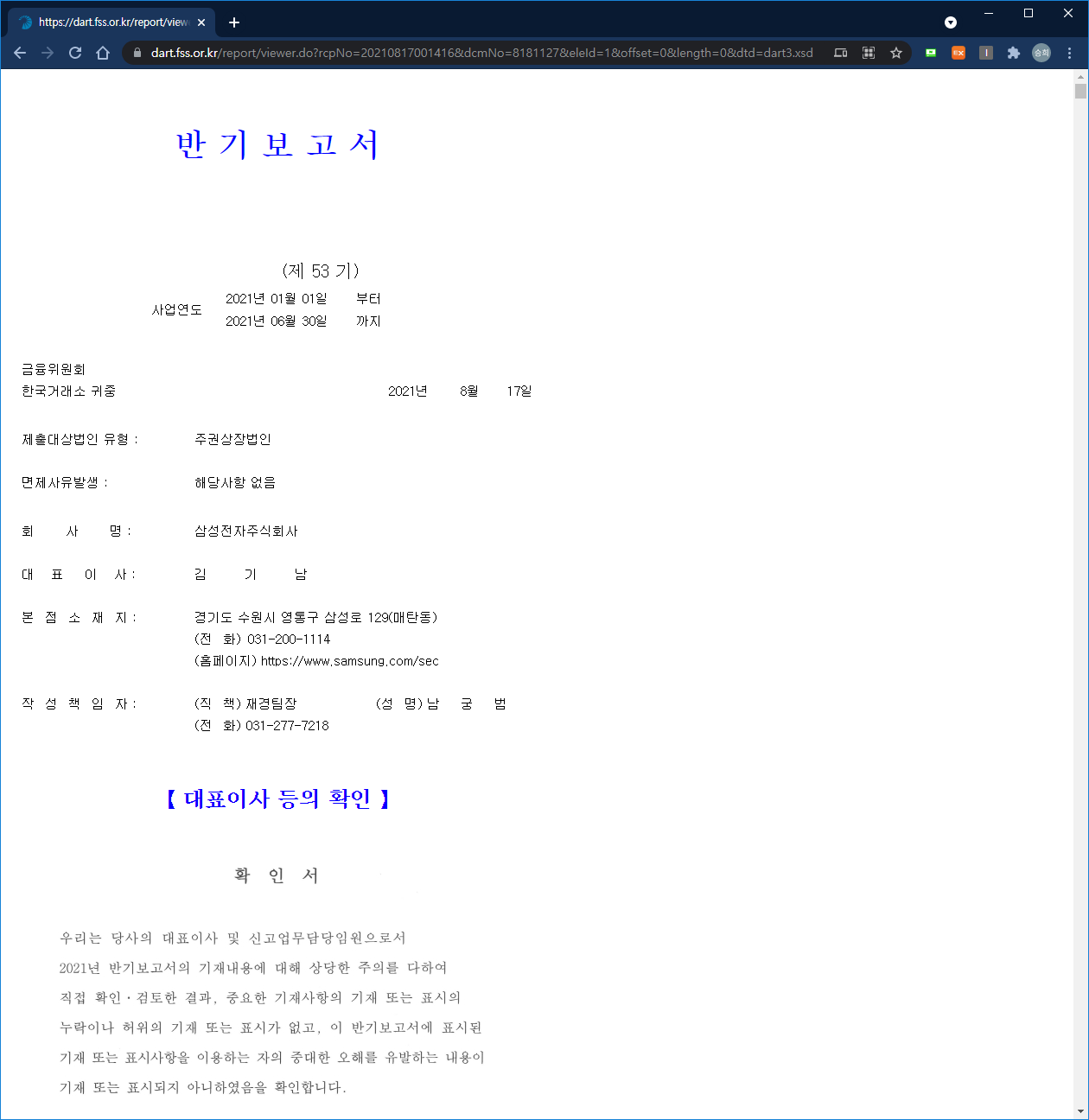
urllib 라이브러리의 parse 모듈을 사용해서 url의 query 인자를 바꿔보자
import urllib.parse
url_dart = 'https://dart.fss.or.kr{}'
url_src = url_dart.format(src)
url_parsed = urllib.parse.urlparse(url_src)
# ParseResult(scheme='https', netloc='dart.fss.or.kr', path='/report/viewer.do', params='', query='rcpNo=20210817001416&dcmNo=8181127&eleId=1&offset=670&length=4089&dtd=dart3.xsd', fragment='')
queries = url_parsed.query.split('&')
queries_split = [x.split('=') for x in queries]
queries_dict = {}
for q in queries_split:
queries_dict[q[0]] = q[1]
queries_dict['offset'] = '0'
queries_dict['length'] = '0'
queries = '&'.join([f'{x[0]}={x[1]}' for x in queries_dict.items()])
url_parsed = url_parsed._replace(query=queries)
# ParseResult(scheme='https', netloc='dart.fss.or.kr', path='/report/viewer.do', params='', query='rcpNo=20210817001416&dcmNo=8181127&eleId=1&offset=0&length=0&dtd=dart3.xsd', fragment='')
url_src = url_parsed.geturl()In [4]: url_src
Out[4]: 'https://dart.fss.or.kr/report/viewer.do?rcpNo=20210817001416&dcmNo=8181127&eleId=1&offset=0&length=0&dtd=dart3.xsd'이제 바뀐 url로 request해보자
from lxml import etree
response = session.get(url_src)
# render javascript
response.html.render()
element = response.html.lxml
# modify link tag - css reference address
tag_link = element.find('.//link')
tag_link.attrib['href'] = url_dart.format(tag_link.attrib['href'])
# modify img tag - src address
tag_img = element.findall('.//img')
for tag in tag_img:
tag.attrib['src'] = url_dart.format(tag.attrib['src'])
print(tag.attrib['src'])
# save html file in local
treestr = etree.tostring(element, encoding='utf-8', method='html', pretty_print=True).decode('utf-8')
with open('./test.html', 'w', encoding='utf-8') as fp:
fp.write(treestr)렌더링 한 후에 <link> 태그와 <img> 태그의 속성을 변경해줬다
렌더링 직후의 태그 원문은 다음과 같다
<link rel="stylesheet" type="text/css" href="/css/report_xml.css">
<img src="/report/download.do?dcmNo=8181127&flNm=21%EB%85%84+%EB%B0%98%EA%B8%B0+%EB%B3%B4%EA%B3%A0%EC%84%9C+%ED%99%95%EC%9D%B8%EC%84%9C.jpg" width="527" height="756" alt="이미지: 21년 반기 보고서 확인서" onerror="this.removeAttribute('width');this.removeAttribute('height');this.src='/images/common/no_link.gif'">
<img src="/report/download.do?dcmNo=8181127&flNm=%EC%97%B0%EA%B5%AC%EA%B0%9C%EB%B0%9C%EC%A1%B0%EC%A7%81%EB%8F%84.jpg" width="600" height="443" alt="이미지: 연구개발조직도" onerror="this.removeAttribute('width');this.removeAttribute('height');this.src='/images/common/no_link.gif'">href와 src 속성이 모두 상대주소로 되어 있기 때문에, 위에서 했던 것과 동일하게 dart 페이지 주소를 앞에 첨부해주면 다음과 같이 변경할 수 있다
<link rel="stylesheet" type="text/css" href="https://dart.fss.or.kr/css/report_xml.css">
<img src="https://dart.fss.or.kr/report/download.do?dcmNo=8181127&flNm=21%EB%85%84+%EB%B0%98%EA%B8%B0+%EB%B3%B4%EA%B3%A0%EC%84%9C+%ED%99%95%EC%9D%B8%EC%84%9C.jpg" width="527" height="756" alt="이미지: 21년 반기 보고서 확인서" onerror="this.removeAttribute('width');this.removeAttribute('height');this.src='/images/common/no_link.gif'">
<img src="https://dart.fss.or.kr/report/download.do?dcmNo=8181127&flNm=%EC%97%B0%EA%B5%AC%EA%B0%9C%EB%B0%9C%EC%A1%B0%EC%A7%81%EB%8F%84.jpg" width="600" height="443" alt="이미지: 연구개발조직도" onerror="this.removeAttribute('width');this.removeAttribute('height');this.src='/images/common/no_link.gif'">lxml 패키지의 etree 모듈을 사용해서 <html> Element를 문자열로 변경한 후, 로컬에 test.html 파일명으로 저장한 결과, 3.2MByte의 파일이 생성되었다 (용량이 상당히 크다...)
notepad++ 등 에디터로 html 파일을 열어보면 인코딩 문제없이 제대로 저장된 것을 볼 수 있다

이제 대망의 마지막 단계!
크롬과 같은 브라우저로 html 파일을 열어보자

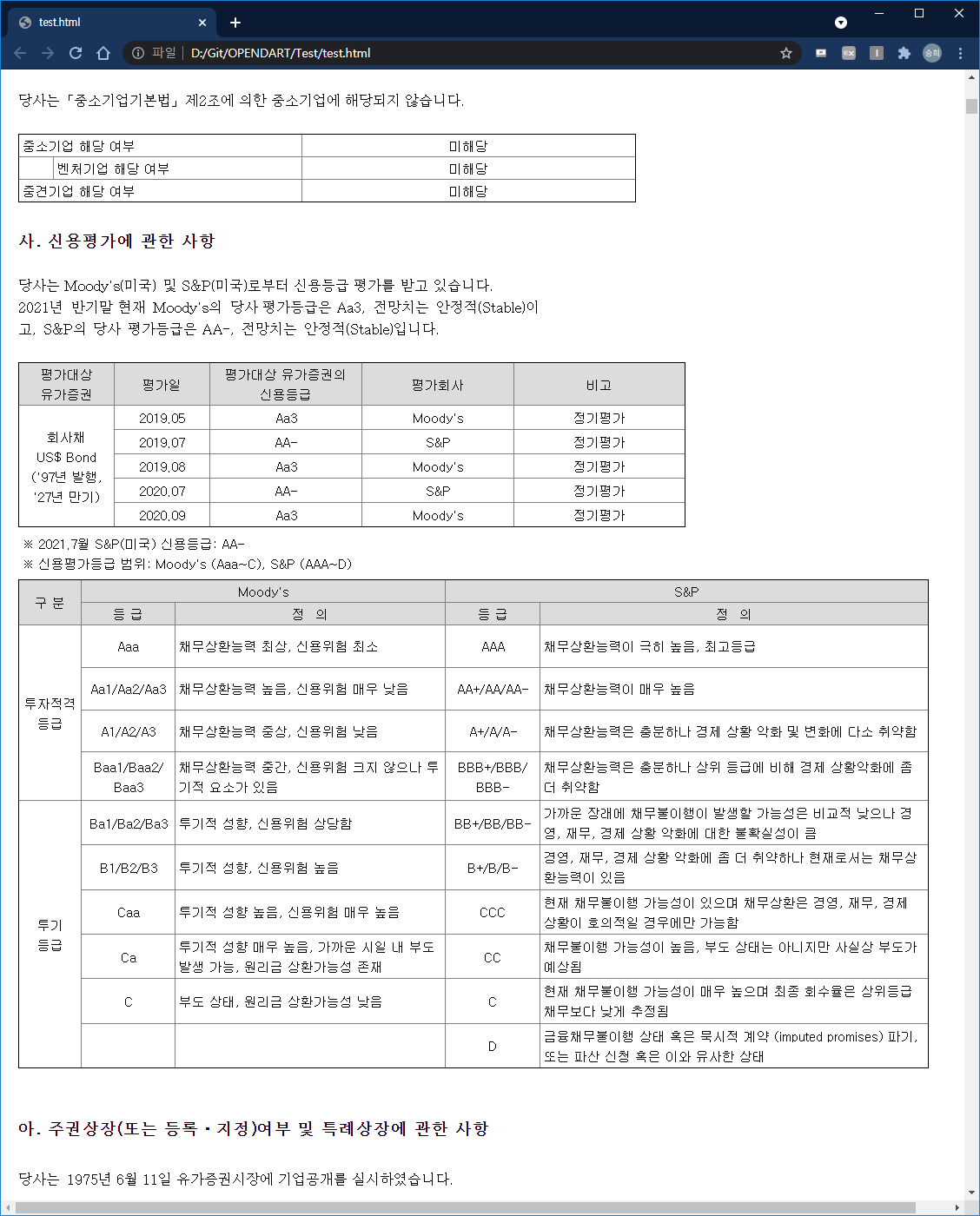
dart 홈페이지로부터 css 파일을 불러와서 스타일이 제대로 설정되어 폰트, 색상, 표 등이 제대로 그려지며, '확인서'같은 이미지(jpg)파일도 정상적으로 그려지는 것을 알 수 있다

왼쪽 브라우저창이 dart 홈페이지에서 보는 리포터 뷰어이고, 오른쪽이 작성된 코드를 토대로 로컬에 저장된 html 파일을 불러온 결과다 (대충 비교해보니 차이가 없다)
GOOD!

테스트에 사용된 전체 코드는 다음과 같다
import time
import urllib.parse
from lxml import etree
from requests_html import HTMLSession
rcpNo = '20210817001416'
url_doc = 'https://dart.fss.or.kr/dsaf001/main.do?rcpNo={}'.format(rcpNo)
url_dart = 'https://dart.fss.or.kr{}'
session = HTMLSession()
response = session.get(url_doc)
# render javascript
tm_start = time.perf_counter()
response.html.render()
elapsed = time.perf_counter() - tm_start
src = response.html.lxml.get_element_by_id("ifrm").attrib.get('src')
# change query attribute (offset, length)
url_src = url_dart.format(src)
url_parsed = urllib.parse.urlparse(url_src)
queries = url_parsed.query.split('&')
queries_split = [x.split('=') for x in queries]
queries_dict = {}
for q in queries_split:
queries_dict[q[0]] = q[1]
queries_dict['offset'] = '0'
queries_dict['length'] = '0'
queries = '&'.join([f'{x[0]}={x[1]}' for x in queries_dict.items()])
url_parsed = url_parsed._replace(query=queries)
url_src = url_parsed.geturl()
# request dart document url and render
response = session.get(url_src)
response.html.render()
element = response.html.lxml
# modify link tag - css reference address
tag_link = element.find('.//link')
tag_link.attrib['href'] = url_dart.format(tag_link.attrib['href'])
# modify img tag - src address
tag_img = element.findall('.//img')
for tag in tag_img:
tag.attrib['src'] = url_dart.format(tag.attrib['src'])
treestr = etree.tostring(element, encoding='utf-8', method='html', pretty_print=True).decode('utf-8')
with open('./test.html', 'w', encoding='utf-8') as fp:
fp.write(treestr)
session.close()전체 과정을 정리해보자
- dart에 특정 문서 번호(rcpNo)를 불러오는 url (dsaf001/main.do) 호출
- 호출 결과 reponse를 render하여 자바스크립트 실행이 완료된 html 획득
- js 렌더링 후 html 내부의 <iframe> 태그의 src 속성에 기입된 원문 호출 url 획득 (url_src)
- 문서 전체를 가져오기 위해 url_src 쿼리 인자 중 offset과 length를 모두 0으로 수정
- 원문 호출 url request 후 자바스크립트 실행의 위해 render
- 렌더링된 html 중 <link>와 <img> 태그의 상대주소를 절대주소로 수정
- html 문자열을 로컬에 파일로 저장
자바스크립트 렌더링 시퀀스가 2차례나 있는데, 렌더링 1번당 2초 넘게 수행되니 상당히 오래 걸린다
(애초에 예시로 든 문서 자체가 용량이 상당히 크다)
여러 개의 문서 원문을 다운로드받고자 할 경우 코루틴 구현은 필수라 할 수 있다
한 번 다운로드 받아두면 굳이 재검색을 위해 dart 홈페이지를 재방문할 필요가 없어지기 때문에 편리해지고, 크롤링도 상당히 간편해진다 (dart viewer에서 원문 크롤링을 해보니 약간 번거롭다)
하지만! 내가 구현한 방식은 dart의 홈페이지 운용방침에 따라 변경될 여지가 많기 때문에 꾸준히 추적해나가야 한다는 단점이 있다... ㅠ (변경사항 생기면 포스트 업데이트하지 뭐 ㅎㅎ)
이상, dart의 공시자료 원문을 html 파일로 로컬에 저장하는 방법을 알아보았다
위 코드로 정상동작하지 않는 문서들이 분명히 있을 것 같지만... 일단은 마무리하도록 한다
끝~!
[2021.10.01 추가]
좀 더 깔끔한 방법을 찾았다
render시에 javascript로
currentDocValues;를 호출해주면 dcmNo를 훨씬 깔끔하게 얻을 수 있다
예제코드는 async 비동기 코루틴으로 작성해봤다
import asyncio
import lxml.etree as etree
from requests_html import AsyncHTMLSession
async def func(doc_no: str):
asession = AsyncHTMLSession()
url1 = 'https://dart.fss.or.kr/dsaf001/main.do'
params1 = {'rcpNo': doc_no}
script = "currentDocValues;"
response = await asession.get(url1, params=params1)
params2 = await response.html.arender(script=script)
print(f'get document values - {params2}')
params2['offset'] = 0
params2['length'] = 0
url2 = 'https://dart.fss.or.kr/report/viewer.do'
response = await asession.get(url2, params=params2)
await asession.close()
tree = response.html.lxml
# encoding =response.encoding
encoding = response.html.encoding # 2022.03.05 수정
tag_link = tree.find('.//link')
tag_link.attrib['href'] = "https://dart.fss.or.kr{}".format(tag_link.attrib['href'])
tags_img = tree.findall('.//img')
for tag in tags_img:
tag.attrib['src'] = "https://dart.fss.or.kr{}".format(tag.attrib['src'])
str_enc = etree.tostring(tree, encoding=encoding, method='html', pretty_print=True)
str_dec = str_enc.decode(encoding)
with open(f'./{doc_no}.html', 'w', encoding=encoding) as fp:
fp.write(str_dec)
print('save done...')
try:
loop = asyncio.get_running_loop()
loop.create_task(func('20210827000120'))
except RuntimeError:
asyncio.run(func('20210827000120'))실행결과
get document values - {'rcpNo': '20210827000120', 'dcmNo': '8195082', 'eleId': '1', 'offset': '736', 'length': '10501', 'dtd': 'dart3.xsd'}
save done...'Data Analysis > Data Engineering' 카테고리의 다른 글
| 공공데이터포털::한국예탁결제원 주식정보서비스 (REST API) (0) | 2021.12.19 |
|---|---|
| 웹크롤링 - 금융감독원 전자공시시스템(DART) 특정일자 공시문서 전체 리스트 크롤링 (4) | 2021.10.01 |
| 금융감독원::OPENDART 전자공시 Open API 사용하기 (11) | 2021.09.18 |
| 공공데이터포털::전기차 충전소 운영정보 조회 (REST API) (2) | 2021.06.25 |
| 공공데이터포털::공휴일 데이터 조회 (REST API) (8) | 2021.04.03 |



