
YOGYUI
웹크롤링 - Yahoo Finance 주가지수 이력 가져오기 본문

Web Crawling - Get historical data of stock index from Yahoo Finance
야후 파이낸스 (yahoo finance)는 개발자들이 API로 만들어놓은게 워낙 많아서 굳이 직접 구현할 필요는 없다
(파이썬만 해도 yfinance, Yahoo_fin 등 다양한 종류의 패키지가 존재하므로 사용자 입맛에 맞게 선택해 사용하면 된다)
어차피 야후에서 공식적으로 제공하는 Web API는 없어서 대다수 패키지는 야후 파이낸스 홈페이지 HTML에서 원하는 정보를 웹스크래핑해오는 방식을 취하고 있으므로 웹페이지 변경 시 패키지도 같이 업데이트해야하는 단점이 있으므로, 웹크롤링을 직접 구현해보도록 하자 (어차피 크롤링 연습 포스팅의 일환 ㅎㅎ)
※ 이 글에서는 여러 주가 지수 (KOSPI, S&P, NASDAQ 등)의 1달치 지수 변동 이력(historical data)을 웹페이지로부터 가져와서 시각화까지 해보는 실습을 다루도록 한다
1. 야후 파이낸스 홈페이지 URL 구조 확인
야후 파이낸스 홈페이지 상단 검색창에 S&P 500을 입력해보자 (S&P 500 지수 위키백과)

^GSPC 가 S&P 500 지수를 가리키는 약어다
화면 아래쪽에서 'Historical Data'를 클릭해보자

조회 일자는 default로 오늘로부터 1년전까지의 데이터가 조회된다
Time Period를 1개월치로 조정해보자 (조정 후 Apply 버튼 클릭)

1달치 지수의 데이터를 테이블 형식으로 확인할 수 있다 (주말, 공휴일 등 휴장일은 자동으로 제외됨)
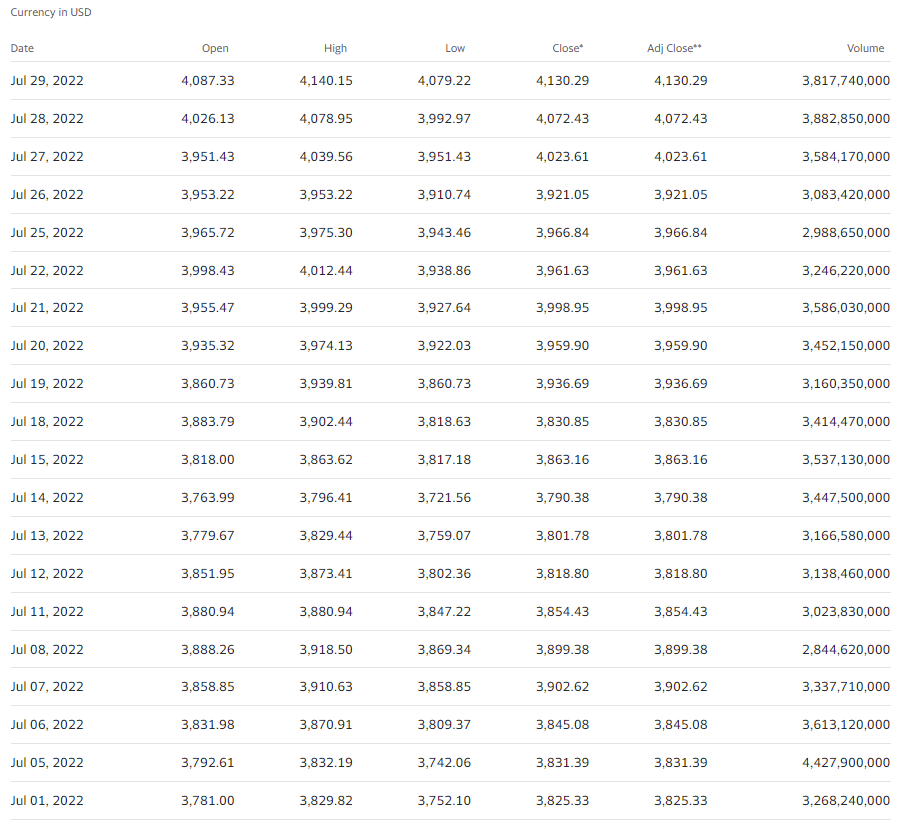
각 항목의 의미는 다음과 같다
- Open: 시작가
- High: 장중 최고
- Low: 장중 최저
- Close*: 종가 (주식분할 반영)
- Adj Close**: 조정 종가 (주식분할, 배당 및 분배금 반영)
- Volume: 거래량
이제 웹브라우저의 URL을 확인해보자

https://finance.yahoo.com/quote/%5EGSPC/history?period1=1656633600&period2=1659312000&interval=1d&filter=history&frequency=1d&includeAdjustedClose=true
- 종목코드에 해당하는 ^GSPC 가 URL에서는 %5EGSPC로 퍼센트 인코딩되어 있다 (percent-encoding 위키백과)
- 조회시작시점 period1과 조회종료시점 period2는 모두 timestamp값이 인자로 사용된다
여기서 timestamp란, 1970년 1월 1일 0시 0분 0초로부터 특정 시점까지의 흐른 초(second)로, 보통 UNIX 혹은 POSIX timestamp라고 부른다
간단하게 파이썬의 datetime 패키지를 사용하면 UNIX 타임스탬프 값을 변환할 수 있다
import datetime
ts1 = 1656633600
ts2 = 1659312000
dt1 = datetime.datetime.fromtimestamp(ts1)
dt2 = datetime.datetime.fromtimestamp(ts2)
print(dt1)
print(dt2)2022-07-01 09:00:00
2022-08-01 09:00:00시점은 각 날짜별 오전 9시 (주식 시장 개시 시점)의 타임스탬프가 사용되는 것을 알 수 있다
따라서, 특정 지수, 특정 월의 1달간 지수 변동 이력 데이터를 조회하는 URL을 조회하는 함수를 requests 모듈을 활용해 만들 수 있다 (퍼센트 인코딩을 위해 urllib의 parse 모듈도 사용)
※ 한달 뒤 1일의 타임스탬프도 구해야하는데, 월별 총 일수도 다르고 해가 넘어가는 것도 고려해줘야 한다. python에서는 calendar와 datetime의 timedelta를 활용하면 손쉽게 해결 가능
※ HTTP USER-AGENT를 Mozilla로 지정해줘야 데이터를 제대로 얻을 수 있다
import urllib
import calendar
import datetime
import requests
def getResponseYFHistDataMonthly(code: str, year: int, month: int) -> requests.models.Response:
target_month = datetime.datetime(year, month, 1, 9) # 오전 9시
days_in_month = calendar.monthrange(year, month)[1] # 해당 월의 총 일 수 자동 계산
dt1 = target_month # 조회 시작일
dt2 = target_month + datetime.timedelta(days=days_in_month) # 조회 종료일
ts1 = dt1.timestamp() # UNIX 타임스탬프로 변경
ts2 = dt2.timestamp() # UNIX 타임스탬프로 변경
url = "https://finance.yahoo.com/quote/"
url += urllib.parse.quote(code) + "/history" # 종목코드 퍼센트 인코딩
params = {
"period1": int(ts1),
"period2": int(ts2),
"interval": "1d",
"filter": "history",
"frequency": "1d",
"includeAdjustedClose": "true"
}
headers = {
"USER-AGENT": "Mozilla/5.0"
}
return requests.get(url, params=params, headers=headers)함수를 호출하는 순간 야후 파이낸스 웹페이지에 GET 명령으로 데이터를 가져오게 된다
다음과 같이 함수를 호출한 뒤, request시 사용된 URL을 확인해보자
In [1]: response = getResponseYFHistDataMonthly("^GSPC", 2022, 7)
In [2]: response.url
Out[2]: 'https://finance.yahoo.com/quote/%5EGSPC/history?period1=1656633600&period2=1659312000&interval=1d&filter=history&frequency=1d&includeAdjustedClose=true'위에서 살펴본 URL과 동일하다!
원본 데이터 문자열도 살펴보자
In [3]: response.text
Out[3]: '<!DOCTYPE html>\n <html lang="en-us"><head>\n <meta http-equiv="content-type" content="text/html; charset=UTF-8">\n <meta charset="utf-8">\n <title>Yahoo</title>\n <meta name="viewport" content="width=device-width,initial-scale=1,minimal-ui">\n <meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">\n <style>\n html {\n height: 100%;\n }\n body {\n background: #fafafc url(https://s.yimg.com/nn/img/sad-panda-201402200631.png) 50% 50%;\n background-size: cover;\n height: 100%;\n text-align: center;\n font: 300 18px "helvetica neue", helvetica, verdana, tahoma, arial, sans-serif;\n }\n table {\n height: 100%;\n width: 100%;\n table-layout: fixed;\n border-collapse: collapse;\n border-spacing: 0;\n border: none;\n }\n h1 {\n font-size: 42px;\n font-weight: 400;\n color: #400090;\n }\n # ... 후략<!DOCTYPE> 태그 뒤에 바로 <html lang="en-us">가 나오면 실제 웹페이지와 동일한 응답을 얻은 것이다
만약 text 내용 중 "status code : 404"와 같은 문자열이 보인다면 야후 파이낸스 서버에서 접근을 차단한 것이니, USER-AGENT 속성을 바꿔보면서 시도해봐야 한다
2. 야후 파이낸스 페이지 구조 분석
이제 웹브라우저의 개발자 도구로 지수 이력 테이블 구조를 분석해보자
(테이블의 최상단 행의 'Jul 29, 2022'로 검색하면 금방 테이블에 해당하는 element를 찾을 수 있다)
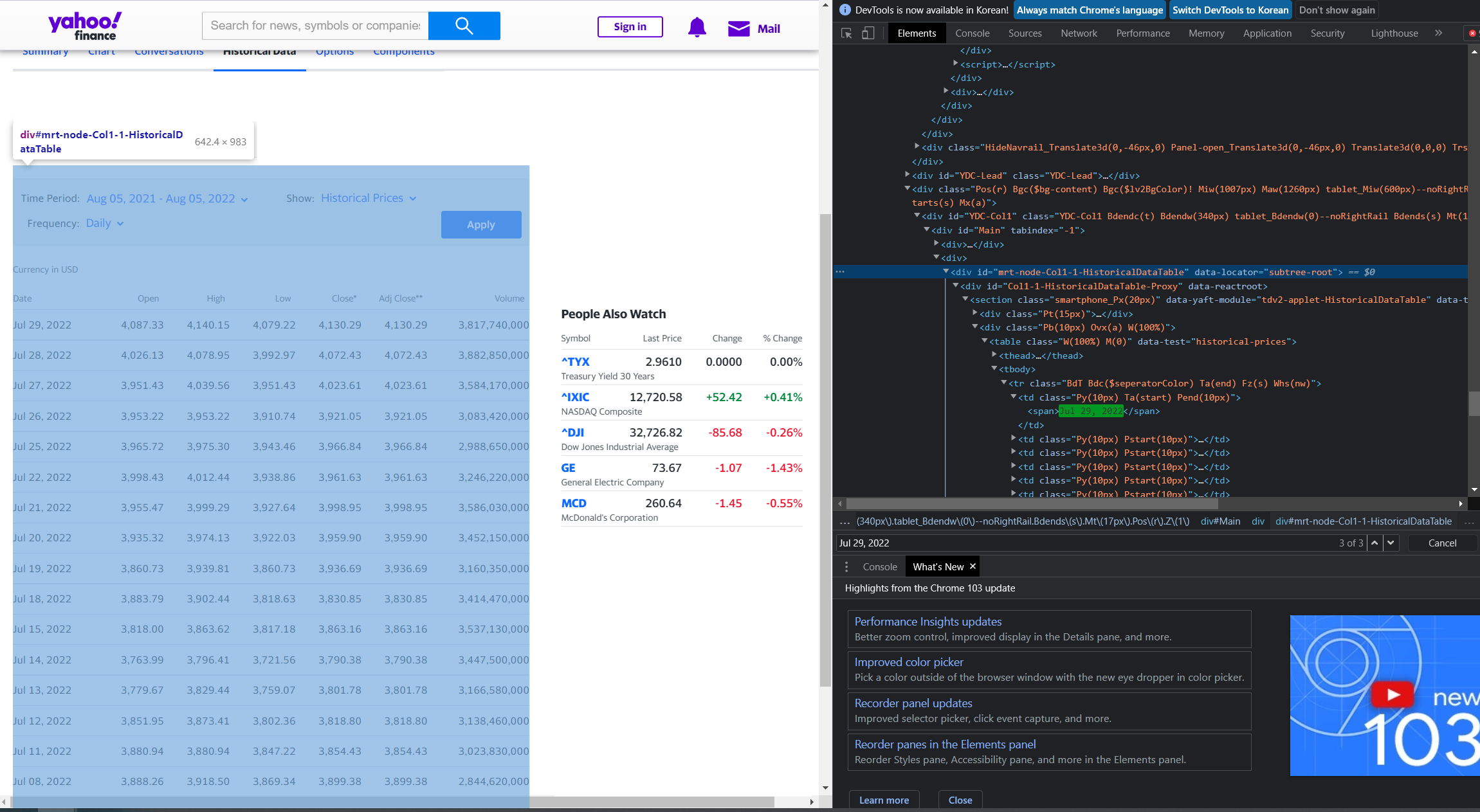
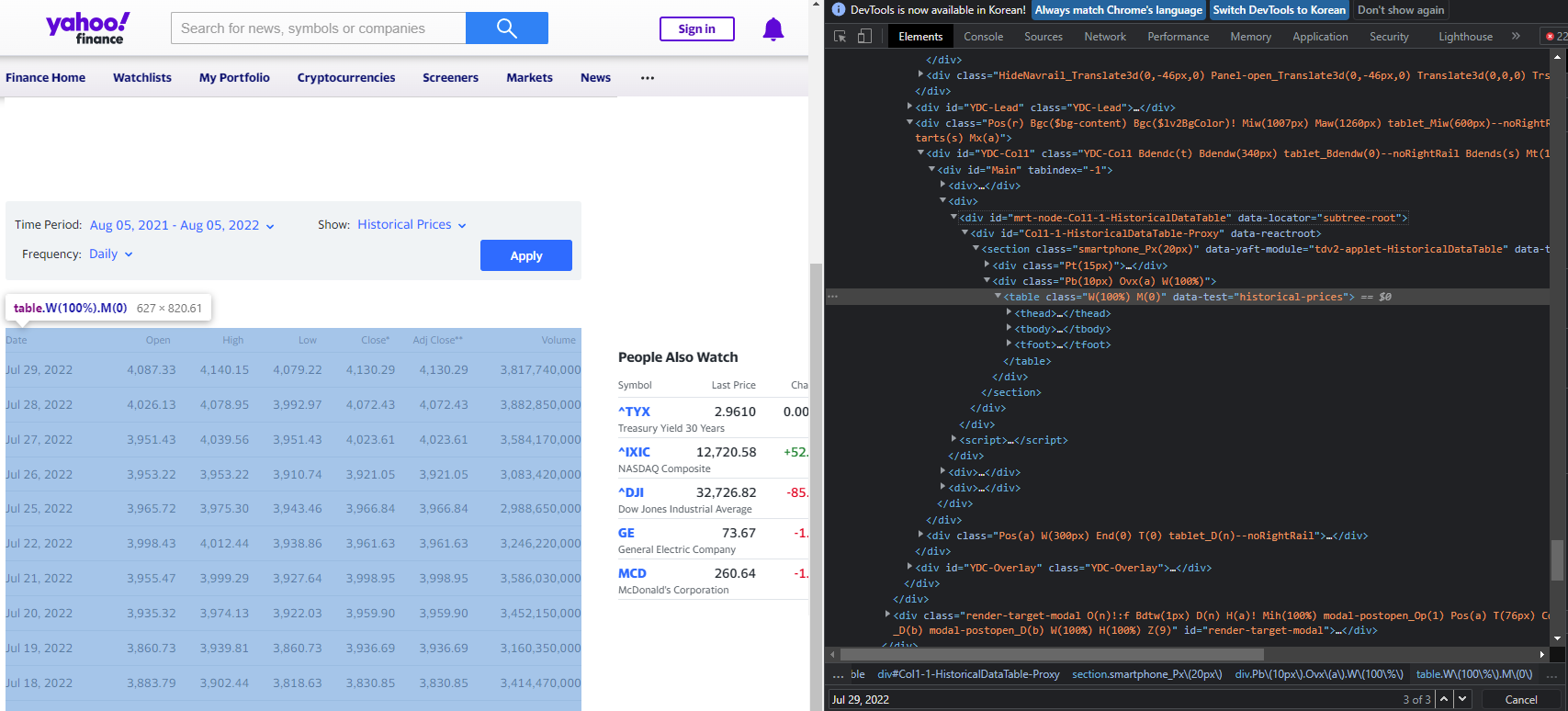
테이블 관련 요소는 <div id="mrt-node-Col1-1-HistoricalDataTable" data-locator="subtree-root"> 태그에 자식으로 존재하며, 테이블 자체는 <table class="W(100%) M(0)" data-test="historical-prices"> 태그로 구현되어 있는 것을 알 수 있다
테이블 태그만 자세히 기록해보면
<table class="W(100%) M(0)" data-test="historical-prices">
<thead>
<tr class="C($tertiaryColor) Fz(xs) Ta(end)">
<th class="Ta(start) W(100px) Fw(400) Py(6px) Pend(6px)"><span>Date</span></th>
<th class="Fw(400) Py(6px) Pend(6px)"><span>Open</span></th>
<th class="Fw(400) Py(6px) Pend(6px)"><span>High</span></th>
<th class="Fw(400) Py(6px) Pend(6px)"><span>Low</span></th>
<th class="Fw(400) Py(6px) Pend(6px)"><span>Close*</span></th>
<th class="Fw(400) Py(6px) Pend(6px) Whs(nw)"><span>Adj Close**</span></th>
<th class="Fw(400) Py(6px) Pend(6px)"><span>Volume</span></th>
</tr>
</thead>
<tbody>
<tr class="BdT Bdc($seperatorColor) Ta(end) Fz(s) Whs(nw)">
<td class="Py(10px) Ta(start) Pend(10px)"><span>Jul 29, 2022</span></td>
<td class="Py(10px) Pstart(10px)"><span>4,087.33</span></td>
<td class="Py(10px) Pstart(10px)"><span>4,140.15</span></td>
<td class="Py(10px) Pstart(10px)"><span>4,079.22</span></td>
<td class="Py(10px) Pstart(10px)"><span>4,130.29</span></td>
<td class="Py(10px) Pstart(10px)"><span>4,130.29</span></td>
<td class="Py(10px) Pstart(10px)"><span>3,817,740,000</span></td>
</tr>
<tr class="BdT Bdc($seperatorColor) Ta(end) Fz(s) Whs(nw)">
<td class="Py(10px) Ta(start) Pend(10px)"><span>Jul 28, 2022</span></td>
<td class="Py(10px) Pstart(10px)"><span>4,026.13</span></td>
<td class="Py(10px) Pstart(10px)"><span>4,078.95</span></td>
<td class="Py(10px) Pstart(10px)"><span>3,992.97</span></td>
<td class="Py(10px) Pstart(10px)"><span>4,072.43</span></td>
<td class="Py(10px) Pstart(10px)"><span>4,072.43</span></td>
<td class="Py(10px) Pstart(10px)"><span>3,882,850,000</span></td>
</tr>
<!-- 중략 -->
</tbody>
<tfoot>
<tr class="BdT Bdc($seperatorColor) C($tertiaryColor) H(36px)">
<td class="Fz(xs)" colspan="7">
<span>*Close price adjusted for splits.</span>
<span class="Mstart(20px)">
<span>**Adjusted close price adjusted for splits and dividend and/or capital gain distributions.</span>
</span>
</td>
</tr>
</tfoot>
</table>HTML로 테이블 표현할 때 범용적으로 사용하는 <table>, <tbody>, <tr>, <td> 태그들이 보인다
모든 문자열들이 <span> 태그로 구현되어 있기 때문에 파싱(parsing)도 굉장히 쉽게 구현할 수 있을 것 같다
3. HTML 파싱 후 pandas DataFrame으로 변환
이제 야후 파이낸스 페이지로부터 받은 HTML에서 원하는 테이블 영역 태그만 떼어내서 순차적으로 값을 가져온 뒤 pandas DataFrame으로 변환해보자 (lxml 사용: raw text를 HTML tree 객체로 변환)
import lxml
from collections import OrderedDict
import pandas as pd
def getYFHistDataMonthly(code: str, year: int, month: int) -> pd.DataFrame:
response = getResponseYFHistDataMonthly(code, year, month)
tree = lxml.html.fromstring(response.text)
table = tree.find_class("W(100%) M(0)")[0] # history 테이블 요소 찾기
# 테이블 칼럼명 가져오기
column_names = []
thead = table.find("thead")
tr = thead.find("tr")
th = tr.findall("th")
for head in th:
span = head.find("span")
column_names.append(span.text)
column_names = [x.replace('*', '') for x in column_names] # 특수문자(*) 지워주기
# 테이블 모든 행 정보 가져오기
tbody = table.find("tbody")
tr = tbody.findall("tr")
data_list = list()
for row in tr:
data = OrderedDict()
td = row.findall("td")
for idx, elem in enumerate(td):
span = elem.find("span")
data[column_names[idx]] = span.text.replace(',', '') # 쉼표 제거
data_list.append(data)
# 데이터프레임 생성
df = pd.DataFrame(data_list)
# 자료형 변경
df["Date"] = pd.to_datetime(df["Date"], format="%b %d %Y")
df["Open"] = df["Open"].astype(float)
df["High"] = df["High"].astype(float)
df["Low"] = df["Low"].astype(float)
df["Close"] = df["Close"].astype(float)
df["Adj Close"] = df["Adj Close"].astype(float)
df["Volume"] = df["Volume"].astype(float)
# 날짜 오름차순으로 정렬
df.sort_values(by="Date", ascending=True, inplace=True, ignore_index=True)
return dfS&P 500 지수의 2022년 7월 히스토리를 가져와보자
In [4]: result = getYFHistDataMonthly("^GSPC", 2022, 7)
In [5]: result
Out[5]:
Date Open High Low Close Adj Close Volume
0 2022-07-01 3781.00 3829.82 3752.10 3825.33 3825.33 3.268240e+09
1 2022-07-05 3792.61 3832.19 3742.06 3831.39 3831.39 4.427900e+09
2 2022-07-06 3831.98 3870.91 3809.37 3845.08 3845.08 3.613120e+09
3 2022-07-07 3858.85 3910.63 3858.85 3902.62 3902.62 3.337710e+09
4 2022-07-08 3888.26 3918.50 3869.34 3899.38 3899.38 2.844620e+09
5 2022-07-11 3880.94 3880.94 3847.22 3854.43 3854.43 3.023830e+09
6 2022-07-12 3851.95 3873.41 3802.36 3818.80 3818.80 3.138460e+09
7 2022-07-13 3779.67 3829.44 3759.07 3801.78 3801.78 3.166580e+09
8 2022-07-14 3763.99 3796.41 3721.56 3790.38 3790.38 3.447500e+09
9 2022-07-15 3818.00 3863.62 3817.18 3863.16 3863.16 3.537130e+09
10 2022-07-18 3883.79 3902.44 3818.63 3830.85 3830.85 3.414470e+09
11 2022-07-19 3860.73 3939.81 3860.73 3936.69 3936.69 3.160350e+09
12 2022-07-20 3935.32 3974.13 3922.03 3959.90 3959.90 3.452150e+09
13 2022-07-21 3955.47 3999.29 3927.64 3998.95 3998.95 3.586030e+09
14 2022-07-22 3998.43 4012.44 3938.86 3961.63 3961.63 3.246220e+09
15 2022-07-25 3965.72 3975.30 3943.46 3966.84 3966.84 2.988650e+09
16 2022-07-26 3953.22 3953.22 3910.74 3921.05 3921.05 3.083420e+09
17 2022-07-27 3951.43 4039.56 3951.43 4023.61 4023.61 3.584170e+09
18 2022-07-28 4026.13 4078.95 3992.97 4072.43 4072.43 3.882850e+09
19 2022-07-29 4087.33 4140.15 4079.22 4130.29 4130.29 3.817740e+09
제대로 가져왔다~~
4. 각종 지수별 월간 등락 시각화
데이터에 시작가, 고가, 저가, 종가 (OHLC) 모두 있으므로, 주식하는 사람들에게는 익숙한 캔들스틱 차트를 그릴 수 있다
matplotlib에 기본으로 설치되어 있진 않고, pip를 통해 mpl_finance 패키지를 설치해줘야 한다
pip install mpl_financeimport matplotlib.pyplot as plt
from mpl_finance import candlestick_ohlc
import matplotlib.dates as mpl_dates
result_snp500 = getYFHistDataMonthly("^GSPC", 2022, 7) # S&P 500
fig, ax = plt.subplots(figsize=(10,6))
temp = result_snp500[["Date", "Open", "High", "Low", "Close"]].copy()
temp["Date"] = pd.to_datetime(temp["Date"])
temp["Date"] = temp["Date"].apply(mpl_dates.date2num)
candlestick_ohlc(ax, temp.values, width=0.6, colorup="red", colordown="blue", alpha=0.8)
date_format = mpl_dates.DateFormatter("%Y.%m.%d")
ax.xaxis.set_major_formatter(date_format)
# 등락율 계산
value1 = temp.iloc[0]["Open"]
value2 = temp.iloc[-1]["Close"]
cal = (value2 - value1) / value1 * 100
title = "S&P 500\n{:g}%".format(cal)
ax.set_title(title)
fig.autofmt_xdate()
fig.tight_layout()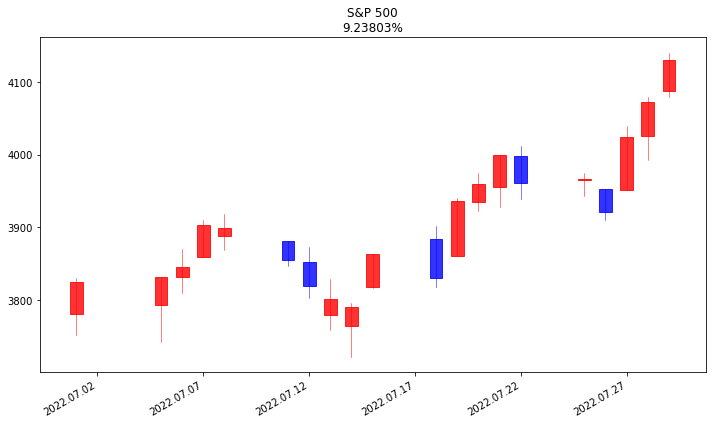
이제 여러 지수들의 1달치 등락율을 함께 그려보자
indices = [
{"name": "S&P 500", "code": "^GSPC"},
{"name": "NASDAQ", "code": "^IXIC"},
{"name": "Dow", "code": "^DJI"},
{"name": "KOSPI", "code": "^KS11"},
{"name": "KOSDAQ", "code": "^KQ11"},
{"name": "NIKKEI 225", "code": "^N225"},
{"name": "HANGSENG", "code": "^HSI"},
{"name": "SHANGHAI", "code": "000001.SS"}
]
for elem in indices:
elem["data"] = getYFHistDataMonthly(elem["code"], 2022, 7)
import matplotlib.pyplot as plt
from mpl_finance import candlestick_ohlc
import matplotlib.dates as mpl_dates
fig, ax = plt.subplots(nrows=4, ncols=2, figsize=(12,12))
date_format = mpl_dates.DateFormatter("%Y.%m.%d")
for i, elem in enumerate(indices):
data = elem["data"][["Date", "Open", "High", "Low", "Close"]].copy()
data["Date"] = pd.to_datetime(data["Date"])
data["Date"] = data["Date"].apply(mpl_dates.date2num)
candlestick_ohlc(ax[i // 2][i % 2], data.values, width=0.6, colorup="red", colordown="blue", alpha=0.8)
ax[i // 2][i % 2].xaxis.set_major_formatter(date_format)
value1 = data.iloc[0]["Open"]
value2 = data.iloc[-1]["Close"]
cal = (value2 - value1) / value1 * 100
title = "{}\n{:g}%".format(elem["name"], cal)
ax[i // 2][i % 2].set_title(title)
fig.autofmt_xdate()
fig.tight_layout()
plt.show()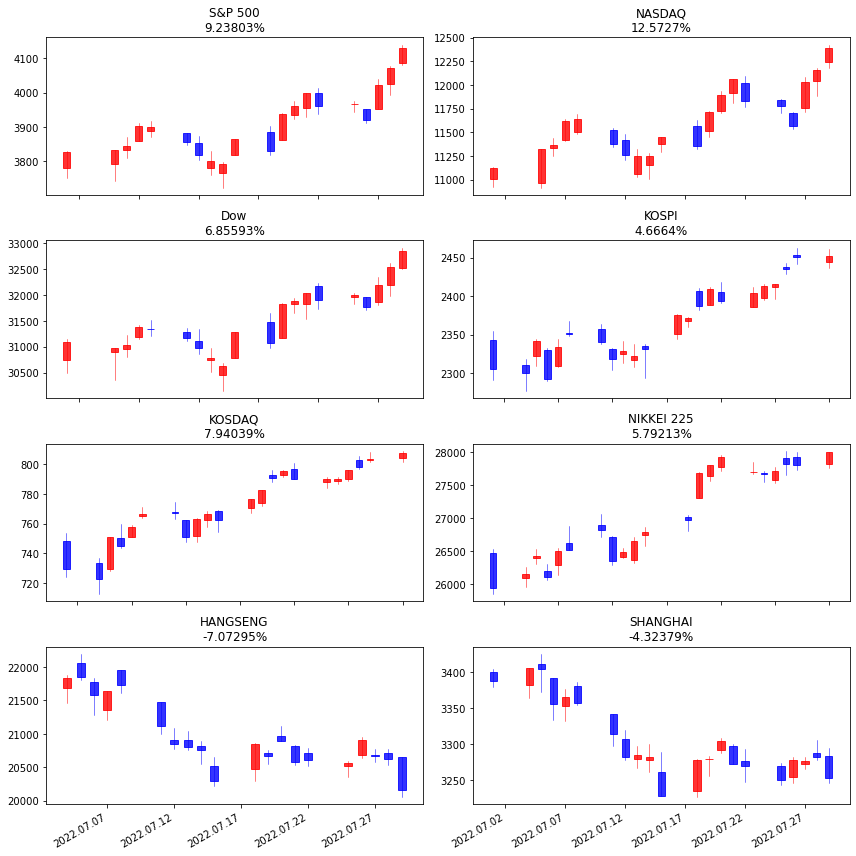
여기서 다룬 크롤링 방법을 활용하면 개별 종목에 대한 차트도 쉽게 그릴 수 있다
차트를 좀 예쁘게 그려보려고 했는데.. 포스팅하다보니 귀찮아져서 PASS~ ㅎㅎ
(애초에 목적은 개별 지수에 대한 1달간 등락률 계산이었다)
끝~!
[참고]
https://algotrading101.com/learn/yahoo-finance-api-guide/
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=kiddwannabe&logNo=221185808375
https://saralgyaan.com/posts/python-candlestick-chart-matplotlib-tutorial-chapter-11/
'Data Analysis > Data Engineering' 카테고리의 다른 글
| 데이터시각화::코로나19 누적확진자 1,000만명 돌파 (0) | 2022.03.24 |
|---|---|
| 웹크롤링 - 한국환경공단(에어코리아) 측정소 정보 가져오기 (0) | 2022.01.13 |
| 공공데이터포털::대기오염정보 조회 (REST API) (0) | 2022.01.12 |
| 웹크롤링 - DART 기업개황 업종별 기업 리스트 가져오기 (Final) (0) | 2022.01.08 |
| 웹크롤링 - DART 기업개황 업종별 기업 리스트 가져오기 (3) (0) | 2022.01.08 |



