
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- Espressif
- 월패드
- 미국주식
- 국내주식
- 파이썬
- 매터
- ConnectedHomeIP
- esp32
- MQTT
- 티스토리챌린지
- 힐스테이트 광교산
- Apple
- 라즈베리파이
- Python
- Home Assistant
- 홈네트워크
- 배당
- raspberry pi
- 취미생활
- 나스닥
- 해외주식
- RS-485
- 오블완
- 공모주
- homebridge
- 현대통신
- matter
- Bestin
- 마이크로소프트
- 애플
- Today
- Total
YOGYUI
웹크롤링 - 금융감독원 전자공시시스템(DART) 특정일자 공시문서 전체 리스트 크롤링 본문
웹크롤링 - 금융감독원 전자공시시스템(DART) 특정일자 공시문서 전체 리스트 크롤링
요겨 2021. 10. 1. 13:52
금융감독원의 전자공시시스템(DART) 홈페이지(https://dart.fss.or.kr/)에서 '최근공시' 메뉴를 활용하면 최근에 전자공시된 모든 유형의 문서를 확인할 수 있다 (시간 - 회사명 - 제출인 정보 제공)
기능은 '최근공시'이지만 검색하고자 하는 날짜를 선택할 수 있기 때문에 특정 요일에 공시된 모든 문서를 리스트업할 수 있다
글을 쓰고 있는 2021년 10월 1일 현재까지는 OpenAPI인 OPENDART로는 제공되지 않는 기능이기 때문에 DART 웹페이지에서 Python을 활용해서 크롤링하는 코드를 작성해보자
1. 웹구조 분석
1.1. URL
특정 날짜를 선택하면 URL이 다음과 같이 변경된다
https://dart.fss.or.kr/dsac001/mainY.do?selectDate=2021.10.01&sort=&series=&mdayCnt=0
(유가증권시장 - 2021년 10월 1일 선택)
공시검색메뉴에 따른 Base URL은 다음과 같다
- 유사증권시장: https://dart.fss.or.kr/dsac001/mainY.do
- 코스닥시장: https://dart.fss.or.kr/dsac001/mainK.do
- 코넥스시장: https://dart.fss.or.kr/dsac001/mainN.do
- 기타법인: https://dart.fss.or.kr/dsac001/mainG.do
- 전체: https://dart.fss.or.kr/dsac001/mainAll.do
- 5%·임원보고: https://dart.fss.or.kr/dsac001/mainO.do
- 펀드공시: https://dart.fss.or.kr/dsac001/mainF.do
파라미터는 사실상 selectDate만 사용하면 된다 (문자열 포맷은 YYYY.mm.dd)
(sort, series는 전체 리스트업하는데 의미가 없고, mdayCnt는 selectDate로부터 얼마나 앞의 날짜를 검색할 것인지 옵션)
웹브라우저의 개발자 도구로 웹문서 구조를 분석해보자
1.2. 테이블 구조

리스트가 담겨있는 테이블 태그 <table>의 class는 tbList이다
<table class="tbList" summary="시간,공시대상회사,보고서명,제출인,접수일자,비고 순으로 되어있습니다.">hierarchy
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ko" lang="ko" class=" ext-strict">
--<body class=" ext-chrome">
----<div class="wrapper subPageBg">
------<div id="container">
--------<div id="contentsWrap">
----------<div id="contents">
------------<div class="tbListWrap" id="listContents">
--------------<div class="tbListInner">
----------------<table class="tbList" summary="시간,공시대상회사,보고서명,제출인,접수일자,비고 순으로 되어있습니다.">테이블 바디 <tbody> 내부의 행 <tr> 구조는 다음과 같다 (보기 쉽게 하기 위해 \n, \t 문자는 모두 제거)
<tr>
<td>10:03</td>
<td class="tL">
<span class="innerWrap">
<span class="tagCom_kospi" title="유가증권시장" style="cursor:default">유</span>
<a href="javascript:openCorpInfoNew('00400857', 'winCorpInfo', '/dsae001/selectPopup.ax');" title="에이블씨엔씨 기업개황 새창">
에이블씨엔씨
</a>
</span>
</td>
<td class="tL">
<a href="/dsaf001/main.do?rcpNo=20211001000043" onclick="openReportViewer('20211001000043'); return false;" id="r_20211001000043" title="합병등종료보고서(합병) 공시뷰어 새창">
합병등종료보고서(합병)
</a>
</td>
<td class="tL ellipsis" title="에이블씨엔씨">에이블씨엔씨</td>
<td>2021.10.01</td>
<td></td>
</tr>총 6개의 테이블 데이터 <td>가 존재하며, 차례대로 시간, 공시대상회사, 보고서명, 제출인, 접수일자, 비고 의 정보를 담고 있다
공시대상회사 및 보고서명은 <a> 태그로 링크가 걸려있다
1.3. Page Navigator
테이블은 최대 100개의 항목만 담을 수 있고, 테이블 아래쪽에 네비게이터가 존재한다

네비게이터 태그는 다음과 같다
<div class="pageSkip">hierarchy
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ko" lang="ko" class=" ext-strict">
--<body class=" ext-chrome">
----<div class="wrapper subPageBg">
------<div id="container">
--------<div id="contentsWrap">
----------<div id="contents">
------------<div class="tbListWrap" id="listContents">
--------------<div class="psWrap">
----------------<div class="pageSkip">태그 구조는 네비게이터 아이템이 <li> 태그로 담겨있는 구조다
<div class="pageSkip">
<ul>
<li class="on">
<a onclick="javascript:void(0);">1</a>
</li>
<li>
<a href="javascript:search(2);">2</a>
</li>
<li>
<a href="javascript:search(3);">3</a>
</li>
<li>
<a href="javascript:search(4);">4</a>
</li>
<li>
<a href="javascript:search(5);">5</a>
</li>
<li>
<a href="javascript:search(6);">6</a>
</li>
<li>
<a href="javascript:search(7);">7</a>
</li>
</ul>
</div>각각 <a> 태그로 링크가 걸려있으며, 링크 클릭 시 자바스크립트 search() 가 호출되는 구조다
search 함수는 HTML 내부 스크립트에 구현되어 있다
function search(page) {
var frm = findForm("searchForm");
if(page=='') page=1;
frm.currentPage.value = page;
xajax.blockUI = false;
xajax.blockTarget = "listContents";
window.scrollTo(0,0);
xajax.sendForm("searchForm", "/dsac001/search.ax", function(str) {
getRef("listContents").innerHTML = str;
$j(".table_list tr:nth-child(even)").addClass("even");
var totalCnt = comma($j("#totalCnt").val());
$j('#txtCB').text(totalCnt);
});
}PHP용 ajax 라이브러리 xajax를 사용하는 것을 알 수 있다
hidden Form인 "searchForm"에 페이지 번호를 대입하여 sendForm으로 POST 방식 호출을 하는 것으로 유추된다
실제로 2번 페이지를 클릭하여 웹브라우저 개발자 도구 네트워크 분석을 해보면~
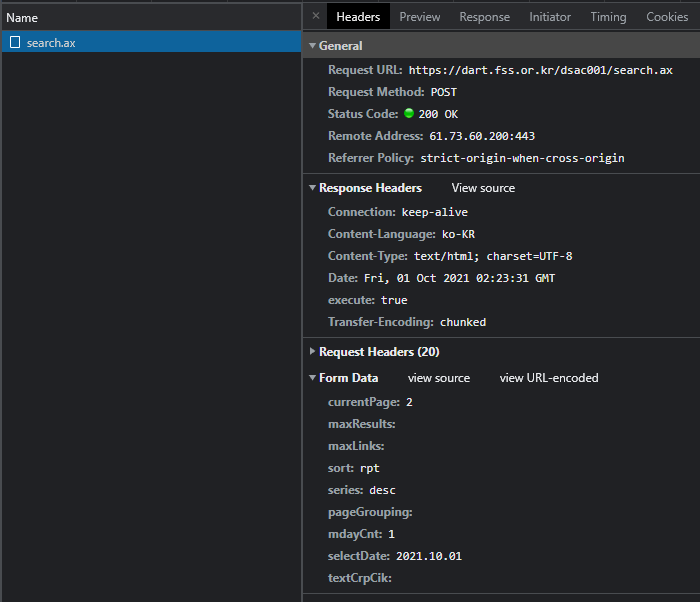
POST 호출로 Form Data에 currentPage=2가 인자로 넘어간 것을 알 수 있다
Form Data 형식은 아래와 같다
currentPage=2&maxResults=&maxLinks=&sort=rpt&series=desc&pageGrouping=Y&mdayCnt=1&selectDate=2021.10.01&textCrpCik=
이제 전체 공시문서 리스트를 가져오기 위한 사전 분석은 대충 완료되었다!
2. Python Prototype
HTML GET, POST만 사용하면 되기 때문에 requests 라이브러리만 사용해도 충분히 구현할 수 있다
(태그 분석은 lxml 라이브러리를 사용하도록 한다)
우선 페이지 개수부터 가져와보자 (예를 위해 2021년 9월 30일 전체(mainAll) 검색
import requests
import lxml.html
url = 'http://dart.fss.or.kr/dsac001/mainAll.do'
params = {'selectDate': '2021.09.30'}
response = requests.get(url, params=params)
tree = lxml.html.fromstring(response.text)
tag_page_skip = tree.find_class('pageSkip')[0]
tag_ul = tag_page_skip.find('ul')
tag_li_list = tag_ul.findall('li')
page_count = len(tag_li_list)In [1]: page_count
Out[1]: 7
7개 페이지 존재여부를 제대로 가져왔다
1번 페이지는 최초 로딩시에 테이블이 전부 로딩되어 있으므로, 다음과 같이 Element로부터 tbList 테이블의 모든 행들을 반환하는 1.2. 에서 분석한대로 함수를 만들어보자
- 보고서명이 <a> 태그의 텍스트로 붙지 않고 <span>의 tail로 붙는 예외사항이 있어서 함께 구현했다
- 보고서번호는 <a> 태그의 id 속성값을 파싱했다
- 회사고유번호는 <a> 태그의 href 속성값을 정규식을 사용해 파싱했다 (8자리 숫자)
import re
def getDocListFromTree(element: lxml.html.HtmlElement) -> list:
tbList = element.find_class('tbList')[0]
tbody = tbList.find('tbody')
tr_list = tbody.findall('tr')
element_list = []
corp_code_regex = re.compile(r"[0-9]{8}")
for tr in tr_list:
# 시간
td_list = tr.findall('td')
strtime = td_list[0].text.strip()
# 공시대상회사
name_span = td_list[1].find('span')
name_a = name_span.find('a')
name = name_a.text
name = name.replace('\t', '')
name = name.replace('\n', '')
name = name.strip()
# 공시대상회사 - 회사고유번호
name_attrib_href = name_a.attrib.get('href')
corp_code_search = corp_code_regex.search(name_attrib_href)
corp_code = ''
if corp_code_search is not None:
span = corp_code_search.span()
corp_code = name_attrib_href[span[0]:span[1]]
# 보고서명
rpt_a = td_list[2].find('a')
rpt = rpt_a.text
if rpt is None:
# <span>의 tail로 붙는 경우가 있음
rpt_span = rpt_a.find('span')
rpt = rpt_span.text + rpt_span.tail
rpt = rpt.replace('\t', '')
rpt = rpt.replace('\n', '')
rpt = rpt.replace(' ', ' ')
rpt = rpt.strip()
# 보고서명 - 보고서번호
rpt_attrib_id = rpt_a.attrib.get('id')
rpt_no = rpt_attrib_id.split('_')[-1]
# 제출인
flr_nm = td_list[3].text
# 접수일자
rcept_dt = td_list[4].text
# 비고
tag_rm = td_list[5]
rm = ' '.join([x.text for x in tag_rm.findall('span')])
element = {'시간': strtime, '고유번호': corp_code, '공시대상회사': name, '보고서명': rpt, '보고서번호': rpt_no, '제출인': flr_nm, '접수일자': rcept_dt, '비고': rm}
element_list.append(element)
return element_list
테스트를 위해 5건만 출력해보자
In [2]: print('\n'.join([str(x) for x in getDocListFromTree(tree)[:5]]))
Out[2]:
{'시간': '19:36', '고유번호': '00110875', '공시대상회사': '대신정보통신', '보고서명': '거래처와의거래중단', '보고서번호': '20210930900921', '제출인': '대신정보통신', '접수일자': '2021.09.30', '비고': '코'}
{'시간': '18:32', '고유번호': '00861997', '공시대상회사': '인포마크', '보고서명': '[첨부추가]주요사항보고서(유상증자결정)', '보고서번호': '20210929000599', '제출인': '인포마크', '접수일자': '2021.09.30', '비고': ''}
{'시간': '18:20', '고유번호': '00313649', '공시대상회사': '현대바이오', '보고서명': '투자판단관련주요경영사항 (COVID-19 치료제 CP-COV03의 1상 임상시험계획 신청서 제출)', '보고서번호': '20210930900900', '제출인': '현대바이오', '접수일자': '2021.09.30', '비고': '코'}
{'시간': '18:14', '고유번호': '00187725', '공시대상회사': '코콤', '보고서명': '[기재정정]신규시설투자등', '보고서번호': '20210930900911', '제출인': '코콤', '접수일자': '2021.09.30', '비고': '코'}
{'시간': '18:10', '고유번호': '00288343', '공시대상회사': '삼영이엔씨', '보고서명': '주요사항보고서(소송등의제기)', '보고서번호': '20210930000675', '제출인': '삼영이엔씨', '접수일자': '2021.09.30', '비고': ''}
제대로 된다!
3. Full Document List Up
이제 1.3.에서 분석한 대로 각 페이지별로 POST request를 수행해보자
1번 페이지는 url 최초 로딩 시에 로딩이 되어 있으므로 2번 페이지부터 POST해보자
for page_no in range(1, page_count):
url = 'https://dart.fss.or.kr/dsac001/search.ax'
data = {
'currentPage': page_no + 1,
'selectDate': '2021.09.30',
'mdayCnt': 0
}
response = requests.post(url, data=data)
tree = lxml.html.fromstring(response.text)
doc_list_page = getDocListFromTree(tree)
doc_list.extend(doc_list_page)In [3]: len(doc_list)
Out[3]: 688
In [4]: print('\n'.join([str(x) for x in getDocListFromTree(tree)[-5:]]))
Out[4]:
{'시간': '07:30', '고유번호': '01490990', '공시대상회사': '케이비국민카드제칠차유동화전문유한회사', '보고서명': '[기재정정]자산양도등의등록신청서', '보고서번호': '20210914000183', '제출인': '케이비국민카드', '접수일자': '2021.09.14', '비고': ''}
{'시간': '07:30', '고유번호': '01583740', '공시대상회사': '티월드제육십팔차유동화전문유한회사', '보고서명': '투자설명서', '보고서번호': '20210929000601', '제출인': '티월드제육십팔차유동화전문유한회사', '접수일자': '2021.09.30', '비고': ''}
{'시간': '07:30', '고유번호': '01350416', '공시대상회사': '파인더제일차유동화전문유한회사', '보고서명': '[기재정정]자산양도등의등록신청서', '보고서번호': '20210923000188', '제출인': '삼성카드', '접수일자': '2021.09.23', '비고': ''}
{'시간': '07:30', '고유번호': '00662952', '공시대상회사': '휘닉스중앙에프앤비', '보고서명': '동일인등출자계열회사와의상품ㆍ용역거래변경', '보고서번호': '20210929000605', '제출인': '휘닉스중앙에프앤비', '접수일자': '2021.09.30', '비고': '공'}
{'시간': '07:30', '고유번호': '00662952', '공시대상회사': '휘닉스중앙에프앤비', '보고서명': '동일인등출자계열회사와의상품ㆍ용역거래변경', '보고서번호': '20210929000603', '제출인': '휘닉스중앙에프앤비', '접수일자': '2021.09.30', '비고': '공'}
2021년 9월 30일에 공시죈 전체 688건의 문서를 정상적으로 가져온 것을 알 수 있다
4. Wrap-up
위에서 구현한 프로토타입 코드를 하나의 함수로 구현하면 다음과 같다
- 리스트를 pandas Dataframe으로 변환
import re
import requests
import lxml.html
import pandas as pd
def getDocListFromTree(element: lxml.html.HtmlElement) -> list:
tbList = element.find_class('tbList')[0]
tbody = tbList.find('tbody')
tr_list = tbody.findall('tr')
element_list = []
corp_code_regex = re.compile(r"[0-9]{8}")
for tr in tr_list:
# 시간
td_list = tr.findall('td')
strtime = td_list[0].text.strip()
# 공시대상회사
name_span = td_list[1].find('span')
name_a = name_span.find('a')
name = name_a.text
name = name.replace('\t', '')
name = name.replace('\n', '')
name = name.strip()
# 공시대상회사 - 회사고유번호
name_attrib_href = name_a.attrib.get('href')
corp_code_search = corp_code_regex.search(name_attrib_href)
corp_code = ''
if corp_code_search is not None:
span = corp_code_search.span()
corp_code = name_attrib_href[span[0]:span[1]]
# 보고서명
rpt_a = td_list[2].find('a')
rpt = rpt_a.text
if rpt is None:
# <span>의 tail로 붙는 경우가 있음
rpt_span = rpt_a.find('span')
rpt = rpt_span.text + rpt_span.tail
rpt = rpt.replace('\t', '')
rpt = rpt.replace('\n', '')
rpt = rpt.replace(' ', ' ')
rpt = rpt.strip()
# 보고서명 - 보고서번호
rpt_attrib_id = rpt_a.attrib.get('id')
rpt_no = rpt_attrib_id.split('_')[-1]
# 제출인
flr_nm = td_list[3].text
# 접수일자
rcept_dt = td_list[4].text
# 비고
tag_rm = td_list[5]
rm = ' '.join([x.text for x in tag_rm.findall('span')])
element = {'시간': strtime, '고유번호': corp_code, '공시대상회사': name, '보고서명': rpt, '보고서번호': rpt_no, '제출인': flr_nm, '접수일자': rcept_dt, '비고': rm}
element_list.append(element)
return element_list
def getDartDailyDocumentList(date: str) -> pd.DataFrame:
url = 'http://dart.fss.or.kr/dsac001/mainAll.do'
params = {'selectDate': date}
response = requests.get(url, params=params)
tree = lxml.html.fromstring(response.text)
doc_list = getDocListFromTree(tree)
tag_page_skip = tree.find_class('pageSkip')[0]
tag_ul = tag_page_skip.find('ul')
tag_li_list = tag_ul.findall('li')
page_count = len(tag_li_list)
for page_no in range(1, page_count):
url = 'https://dart.fss.or.kr/dsac001/search.ax'
data = {
'currentPage': page_no + 1,
'selectDate': date,
'mdayCnt': 0
}
response = requests.post(url, data=data)
tree = lxml.html.fromstring(response.text)
doc_list_page = getDocListFromTree(tree)
doc_list.extend(doc_list_page)
df = pd.DataFrame(doc_list)
return dfIn [5]: df = getDartDailyDocumentList('2021.09.30')
In [6]: df.shape
Out[6]: (688, 8)
In [7]: sum(df.duplicated())
Out[7]: 0
In [8]: df.head(5)
Out[8]:
고유번호 공시대상회사 ... 접수일자 제출인
0 00110875 대신정보통신 ... 2021.09.30 대신정보통신
1 00861997 인포마크 ... 2021.09.30 인포마크
2 00313649 현대바이오 ... 2021.09.30 현대바이오
3 00187725 코콤 ... 2021.09.30 코콤
4 00288343 삼영이엔씨 ... 2021.09.30 삼영이엔씨
[5 rows x 8 columns]
In [9]: df.tail(5)
Out[9]:
고유번호 공시대상회사 ... 접수일자 제출인
683 01490990 케이비국민카드제칠차유동화전문유한회사 ... 2021.09.14 케이비국민카드
684 01583740 티월드제육십팔차유동화전문유한회사 ... 2021.09.30 티월드제육십팔차유동화전문유한회사
685 01350416 파인더제일차유동화전문유한회사 ... 2021.09.23 삼성카드
686 00662952 휘닉스중앙에프앤비 ... 2021.09.30 휘닉스중앙에프앤비
687 00662952 휘닉스중앙에프앤비 ... 2021.09.30 휘닉스중앙에프앤비
[5 rows x 8 columns]중복되는 실수없이 함수 호츨 한번으로 전체 리스트를 데이터프레임으로 변환하여 얻어올 수 있다
5. Etc
여러 개의 페이지를 request할 경우 순차적으로 하면 시간이 다소 소요되는 단점이 있다
import time
tm = time.perf_counter()
df = getDartDailyDocumentList('2021.09.30')
elapsed = time.perf_counter() - tmIn [10]: elapsed
Out[10]: 1.41984980000052027개 페이지 요청 및 파싱 소요시간: 1.5초 내외
여러 개의 페이지를 크롤링할 때는 async 코루틴으로 비동기 프로그래밍을 하면 효과적이다
async를 직접 구현하는 것도 어렵지 않지만 약간 번거롭기 때문에 requests-HTML의 AsyncHTMLSession을 사용하면 굉장히 간단하게 비동기 함수를 짤 수 있다
(lxml 객체를 지원하기 때문에 함수 변경도 거의 없다)
import re
import lxml.html
import pandas as pd
from functools import partial
from requests_html import AsyncHTMLSession
def getDartDailyDocumentListAsync(date: str) -> pd.DataFrame:
asession = AsyncHTMLSession()
async def _async_get(url, params):
response = await asession.get(url, params=params)
return response
async def _async_post_parse(url, data):
response = await asession.post(url, data=data)
doc_list = getDocListFromTree(response.html.lxml)
return doc_list
url = 'http://dart.fss.or.kr/dsac001/mainAll.do'
params = {'selectDate': date}
results = asession.run(lambda: _async_get(url, params))
tree = results[0].html.lxml
df = getDocListFromTree(tree)
tag_page_skip = tree.find_class('pageSkip')[0]
tag_ul = tag_page_skip.find('ul')
tag_li_list = tag_ul.findall('li')
page_count = len(tag_li_list)
url = 'https://dart.fss.or.kr/dsac001/search.ax'
if page_count > 1:
data_list = [{
'currentPage': x + 1,
'selectDate': date,
'mdayCnt': 0
} for x in range(1, page_count)]
results = asession.run(*[partial(_async_post_parse, url, x) for x in data_list])
temp = [df]
temp.extend(results)
df = pd.concat(temp)
return dfimport nest_asyncio
nest_asyncio.apply()
import time
tm = time.perf_counter()
df = getDartDailyDocumentListAsync('2021.09.30')
elapsed = time.perf_counter() - tmIn [11]: elapsed
Out[10]: 1.2306523999995989대충 100ms 이상 수행시간을 단축시켰다
(단축율은 15% 수준이니 사실 큰 의미는 없다 ㅋㅋㅋ)
만약 그럴 일은 없겠지만 페이지가 수십개 이상이라면 확실이 비동기 구문의 속도 차이를 체감할 수 있을 것으로 예상한다
테스트하려고 임의로 동일 페이지 여러번 호출하게 만들어봤는데, 몇 번 호출하더니 DART로부터 ban당했다... (서버 과부하 방지를 위해 요청 자체를 블록해버리네)

DART 페이지를 짧은 시간내에 지나치게 많이 호출하지 않도록 주의하자!!
끝~!

[23.03.12] 내용 추가
2023년 3월 11일에 방명록을 통해 버그 리포트가 올라왔다

에러 타입은 IndexError:list index out of range
def getDocListFromTree(element: lxml.html.HtmlElement) -> list:
tbList = element.find_class('tbList')[0]
tbody = tbList.find('tbody')
tr_list = tbody.findall('tr')
element_list = []
corp_code_regex = re.compile(r"[0-9]{8}")
for tr in tr_list:
# 시간
td_list = tr.findall('td')
strtime = td_list[0].text.strip()
# 공시대상회사
name_span = td_list[1].find('span') # >> 에러 발생 부분
# 후략...<tr> 태그 하위에 존재하는 <td> 태그들을 가져와서 인덱싱해야 하는데, <td> 태그가 하나밖에 없는게 문제
실제로 2023년 3월 10일 데이터를 조회해보니
url https://dart.fss.or.kr/dsac001/search.ax?currentPage=12&selectData=2023.03.10&mdayCnt=0
을 조회할 때 오류가 발생했다
page list는 실제로는 11페이지인데, <pageSkip> 태그에서 가져온 <ul>-<li> 태그를 파싱한 결과 14페이지까지 가져오라고 하는 문제가 생긴 듯 하다
일단 <pageSkip> 태그를 파싱하는 부분을 고치는게 맞는 것 같지만, IndexError 예외처리를 해야 다른 문제가 발생하더라도 데이터프레임은 정상적으로 만들 수 있을 것 같으니, 다음과 같이 getDocListFromTree 함수에 try- except 문 하나만 추가해주면 간단하게 문제해결은 가능하다
def getDocListFromTree(element: lxml.html.HtmlElement) -> list:
tbList = element.find_class('tbList')[0]
tbody = tbList.find('tbody')
tr_list = tbody.findall('tr')
element_list = []
corp_code_regex = re.compile(r"[0-9]{8}")
for tr in tr_list:
# 시간
td_list = tr.findall('td')
try: # 추가
strtime = td_list[0].text.strip()
# 공시대상회사
name_span = td_list[1].find('span')
name_a = name_span.find('a')
name = name_a.text
name = name.replace('\t', '')
name = name.replace('\n', '')
name = name.strip()
# 공시대상회사 - 회사고유번호
name_attrib_href = name_a.attrib.get('href')
corp_code_search = corp_code_regex.search(name_attrib_href)
corp_code = ''
if corp_code_search is not None:
span = corp_code_search.span()
corp_code = name_attrib_href[span[0]:span[1]]
# 보고서명
rpt_a = td_list[2].find('a')
rpt = rpt_a.text
if rpt is None:
# <span>의 tail로 붙는 경우가 있음
rpt_span = rpt_a.find('span')
rpt = rpt_span.text + rpt_span.tail
rpt = rpt.replace('\t', '')
rpt = rpt.replace('\n', '')
rpt = rpt.replace(' ', ' ')
rpt = rpt.strip()
# 보고서명 - 보고서번호
rpt_attrib_id = rpt_a.attrib.get('id')
rpt_no = rpt_attrib_id.split('_')[-1]
# 제출인
flr_nm = td_list[3].text
# 접수일자
rcept_dt = td_list[4].text
# 비고
tag_rm = td_list[5]
rm = ' '.join([x.text for x in tag_rm.findall('span')])
element = {'시간': strtime, '고유번호': corp_code, '공시대상회사': name, '보고서명': rpt, '보고서번호': rpt_no, '제출인': flr_nm, '접수일자': rcept_dt, '비고': rm}
element_list.append(element)
except IndexError: # 추가
pass
return element_list예외 발생 시 빈 리스트 (empty list)를 반환하기 때문에 pandas DataFrame 객체를 만드는데는 아무 지장이 없다
위 예외사항을 적용한 전체 코드는 다음과 같다
(데이터프레임을 공시 등록 시간 내림차순으로 정렬한 뒤, 인덱스 초기화하는 구문도 추가)
import re
import lxml.html
import pandas as pd
import requests
from functools import partial
from requests_html import AsyncHTMLSession
def getDocListFromTree(element: lxml.html.HtmlElement) -> list:
tbList = element.find_class('tbList')[0]
tbody = tbList.find('tbody')
tr_list = tbody.findall('tr')
element_list = []
corp_code_regex = re.compile(r"[0-9]{8}")
for tr in tr_list:
# 시간
td_list = tr.findall('td')
try:
strtime = td_list[0].text.strip()
# 공시대상회사
name_span = td_list[1].find('span')
name_a = name_span.find('a')
name = name_a.text
name = name.replace('\t', '')
name = name.replace('\n', '')
name = name.strip()
# 공시대상회사 - 회사고유번호
name_attrib_href = name_a.attrib.get('href')
corp_code_search = corp_code_regex.search(name_attrib_href)
corp_code = ''
if corp_code_search is not None:
span = corp_code_search.span()
corp_code = name_attrib_href[span[0]:span[1]]
# 보고서명
rpt_a = td_list[2].find('a')
rpt = rpt_a.text
if rpt is None:
# <span>의 tail로 붙는 경우가 있음
rpt_span = rpt_a.find('span')
rpt = rpt_span.text + rpt_span.tail
rpt = rpt.replace('\t', '')
rpt = rpt.replace('\n', '')
rpt = rpt.replace(' ', ' ')
rpt = rpt.strip()
# 보고서명 - 보고서번호
rpt_attrib_id = rpt_a.attrib.get('id')
rpt_no = rpt_attrib_id.split('_')[-1]
# 제출인
flr_nm = td_list[3].text
# 접수일자
rcept_dt = td_list[4].text
# 비고
tag_rm = td_list[5]
rm = ' '.join([x.text for x in tag_rm.findall('span')])
element = {
'시간': strtime,
'고유번호': corp_code,
'공시대상회사': name,
'보고서명': rpt,
'보고서번호': rpt_no,
'제출인': flr_nm,
'접수일자': rcept_dt,
'비고': rm
}
element_list.append(element)
except IndexError:
pass
return element_list
def getDartDailyDocumentList(date: str) -> pd.DataFrame:
url = 'http://dart.fss.or.kr/dsac001/mainAll.do'
params = {'selectDate': date}
response = requests.get(url, params=params)
tree = lxml.html.fromstring(response.text)
doc_list = getDocListFromTree(tree)
tag_page_skip = tree.find_class('pageSkip')[0]
tag_ul = tag_page_skip.find('ul')
tag_li_list = tag_ul.findall('li')
page_count = len(tag_li_list)
for page_no in range(1, page_count):
url = 'https://dart.fss.or.kr/dsac001/search.ax'
data = {
'currentPage': page_no + 1,
'selectDate': date,
'mdayCnt': 0
}
response = requests.post(url, data=data)
tree = lxml.html.fromstring(response.text)
doc_list_page = getDocListFromTree(tree)
doc_list.extend(doc_list_page)
return pd.DataFrame(doc_list)
def getDartDailyDocumentListAsync(date: str) -> pd.DataFrame:
asession = AsyncHTMLSession()
async def _async_get(url_, params_):
response = await asession.get(url_, params=params_)
return response
async def _async_post_parse(url_, data):
response = await asession.post(url_, data=data)
doc_list = getDocListFromTree(response.html.lxml)
return pd.DataFrame(doc_list)
url = 'http://dart.fss.or.kr/dsac001/mainAll.do'
params = {'selectDate': date}
results = asession.run(lambda: _async_get(url, params))
tree = results[0].html.lxml
df_ = pd.DataFrame(getDocListFromTree(tree))
tag_page_skip = tree.find_class('pageSkip')[0]
tag_ul = tag_page_skip.find('ul')
tag_li_list = tag_ul.findall('li')
page_count = len(tag_li_list)
url = 'https://dart.fss.or.kr/dsac001/search.ax'
if page_count > 1:
data_list = [{
'currentPage': x + 1,
'selectDate': date,
'mdayCnt': 0
} for x in range(1, page_count)]
results = asession.run(*[partial(_async_post_parse, url, x) for x in data_list])
temp = [df_]
temp.extend(results)
df_ = pd.concat(temp)
return df_
if __name__ == '__main__':
import time
import nest_asyncio
nest_asyncio.apply()
tm = time.perf_counter()
# df = getDartDailyDocumentList('2023.03.10')
df = getDartDailyDocumentListAsync('2023.03.10')
df.sort_values(by='시간', ascending=False, inplace=True)
df.reset_index(inplace=True, drop=True)
elapsed = time.perf_counter() - tm3월 10일의 전체 공시 개수는 1,054개이며,
In [1]: len(df)
Out[1]: 1054
In [2]: df.head(5)
Out[2]:
시간 고유번호 공시대상회사 ... 제출인 접수일자 비고
0 19:56 00409681 아스트 ... 코스닥시장본부 2023.03.10 코
1 19:51 00409681 아스트 ... 아스트 2023.03.10 코
2 19:01 00108065 쎌마테라퓨틱스 ... 유가증권시장본부 2023.03.10 유
3 18:59 00820389 뉴지랩파마 ... 뉴지랩파마 2023.03.10 코
4 18:54 01182578 대유에이피 ... 대유에이피 2023.03.10 코
[5 rows x 8 columns]
In [3]: df.tail(5)
Out[3]:
시간 고유번호 공시대상회사 ... 제출인 접수일자 비고
1049 07:30 01436628 이지스레지던스리츠 ... 이지스레지던스리츠 2023.03.10 정
1050 07:30 00587925 비엘 ... 비엘 2023.03.10
1051 07:30 01263022 BGF리테일 ... BGF리테일 2023.03.10
1052 07:30 00532855 한국유니온제약 ... 금융감독원 2023.03.10
1053 07:30 00398668 휴비츠 ... 휴비츠 2023.03.10
[5 rows x 8 columns]오류없이 정상적으로 읽어오게 된다
나중에 시간있을 때 <pageSkip> 태그 파싱 오류 원인을 파악해봐야겠다 ㅠ
'Data Analysis > Data Engineering' 카테고리의 다른 글
| 웹크롤링 - DART 기업개황 업종별 기업 리스트 가져오기 (1) (0) | 2022.01.06 |
|---|---|
| 공공데이터포털::한국예탁결제원 주식정보서비스 (REST API) (0) | 2021.12.19 |
| 금융감독원::DART 공시문서 js 렌더링된 HTML 가져오기 (4) | 2021.09.24 |
| 금융감독원::OPENDART 전자공시 Open API 사용하기 (17) | 2021.09.18 |
| 공공데이터포털::전기차 충전소 운영정보 조회 (REST API) (2) | 2021.06.25 |



